 Grounding DINO 1.5
Grounding DINO 1.5
# 1 Grounding DINO 1.5
Grounding DINO 1.5: Advance the “Edge” of Open-Set Object Detection
Grounding DINO 1.5:推进开放集目标检测的“边界”
https://github.com/IDEA-Research/Grounding-DINO-1.5-API (opens new window)
2024年6月1日
# 2 摘要
本文介绍了 Grounding DINO 1.5,这是一套由 IDEA Research 开发的先进开放集目标检测模型,旨在推动开放集目标检测的“边界(Edge)”。该套件包括两个模型:
- Grounding DINO 1.5 Pro:一个高性能模型,设计用于在各种场景下具有更强的泛化能力;
- Grounding DINO 1.5 Edge:一个高效模型,针对需要部署在边缘设备的应用场景优化了推理速度。
Grounding DINO 1.5 Pro 在其前作的基础上进一步发展,扩展了模型架构,集成了增强的视觉主干网络,并将训练数据集扩大至超过2000万张带有grounding注释的图像,从而实现了更丰富的语义理解。
Grounding DINO 1.5 Edge 则专为高效运行而设计,减少了特征尺度,但仍保持了强大的检测能力,得益于其在相同的大规模数据集上训练。实验结果表明 Grounding DINO 1.5 的有效性,其中:
- Grounding DINO 1.5 Pro 在 COCO 检测基准上达到了 54.3 的 AP,
- 在 LVIS-minival 零样本迁移测试中达到了 55.7 的 AP,刷新了开放集目标检测的记录。
此外,经过 TensorRT 优化的 Grounding DINO 1.5 Edge 模型在 LVIS-minival 基准下达到了 36.2 的零样本 AP,同时推理速度高达 75.2 FPS,使其更适合边缘计算场景。模型示例和 API 演示将在以下地址发布:https://github.com/IDEA-Research/Grounding-DINO-1.5-API (opens new window)
# 3 引言
本文介绍了 Grounding DINO 1.5,这是由 IDEA Research 开发的一系列强大且实用的开放集目标检测模型。目标检测是计算机视觉中的一项基础任务,近年来的研究重点在于开发具有广泛适应性的通用检测器,能够应对多种真实世界应用场景。提高模型在多样化物体类别中的泛化能力的关键策略之一是引入语言模态信息,这一方向近年来受到了广泛关注并取得了显著进展。
Grounding DINO 是这一领域的重要进展,它基于 Transformer 架构 DINO 构建,并融合了语言信息,使得模型能够在多种场景中执行开放集目标检测。借鉴 GLIP 的思想,Grounding DINO 将目标检测重新定义为短语定位(phrase grounding)任务,从而支持在检测与定位数据集上进行大规模预训练。此外,模型还采用了从几乎无限的图文对中生成的伪标注数据进行自训练,依托强大的架构和语义丰富的数据集,增强了其在开放世界环境下的适用性。
在 Grounding DINO 成功的基础上,Grounding DINO 1.5 在两个关键方向上拓展了模型能力:更强的检测性能和更快的推理速度,分别体现在 Grounding DINO 1.5 Pro 和 Grounding DINO 1.5 Edge 两个版本中。
- Grounding DINO 1.5 Pro 显著扩展了模型容量和数据集规模,旨在构建更强大、更通用的开放集检测模型。具体而言,我们引入了预训练的 ViT-L 架构,并开发了一个数据引擎,能够从多样化来源生成超过2000万张带有grounding标注的图像,从而极大丰富了模型的语义理解能力。
- 相比之下,Grounding DINO 1.5 Edge 专为边缘设备设计,重点关注计算效率,同时不牺牲检测质量。我们设计了一种高效的特征增强模块,仅使用高级图像特征,避免了对多尺度特征的依赖。这一简化策略在训练中使用与 Pro 版本相同的 2000 万图像,仍然保持了模型强大的上下文感知检测能力。
我们的实验结果充分验证了 Grounding DINO 1.5 的优势:
- Grounding DINO 1.5 Pro 在 COCO 零样本迁移测试中达到了 54.3 AP,
- 在 LVIS-minival 和 LVIS-val 零样本测试中分别达到了 55.7 和 47.6 AP,刷新了多个基准测试记录。
此外,Grounding DINO 1.5 Edge 在 TensorRT 优化下达到了 75.2 FPS 的推理速度,并在 LVIS-minival 上实现了 36.2 AP 的零样本性能,使其更加适用于边缘计算场景。
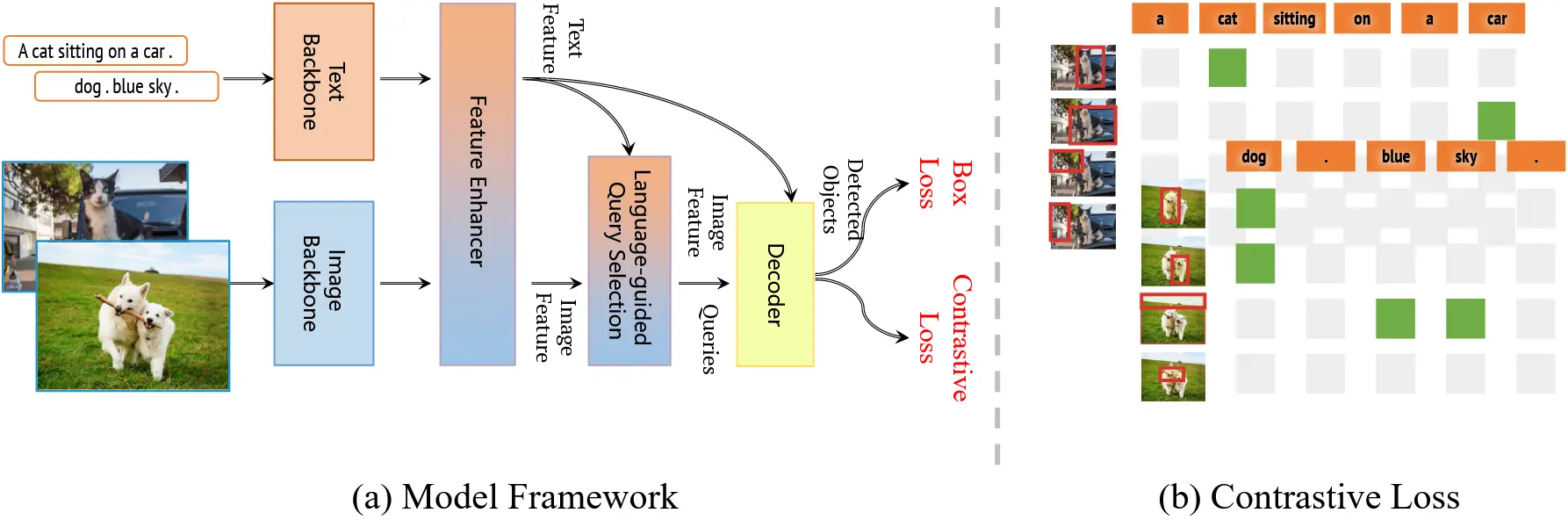
图 1:Grounding DINO 1.5 系列整体框架
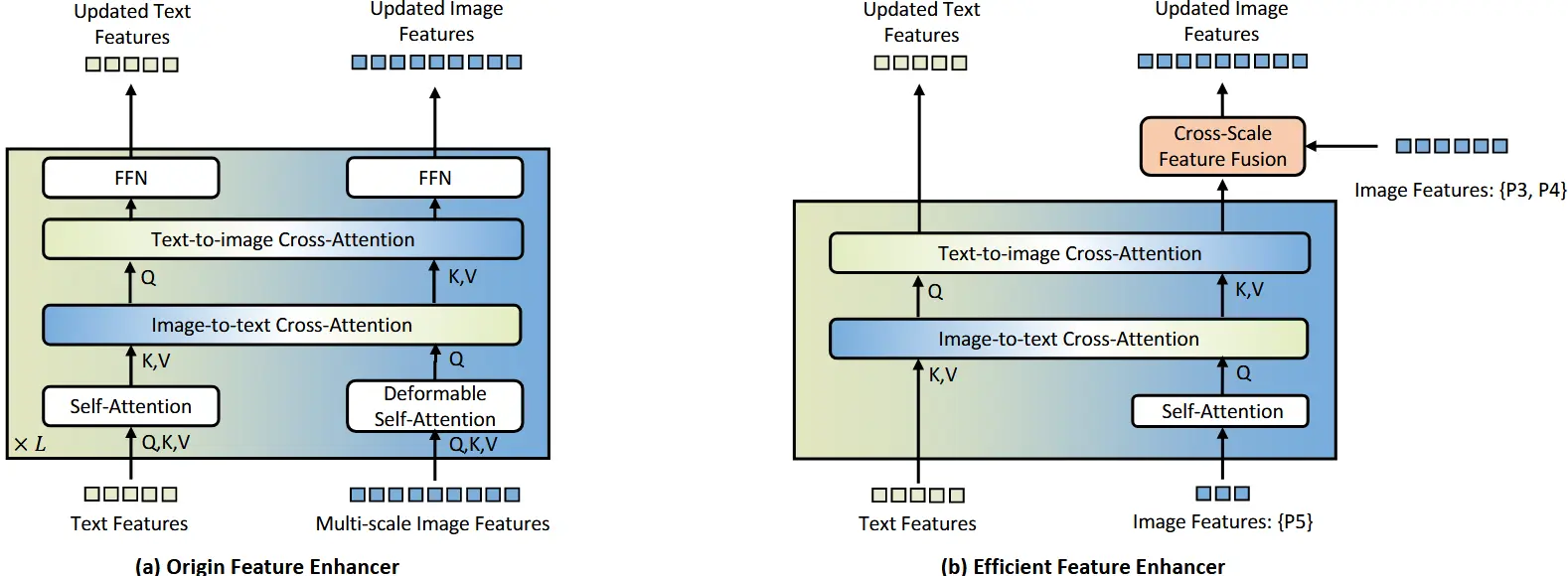
图 2:原始特征增强器与新型高效特征增强器的对比
# 4 模型训练
# 4.1 模型架构
我们在图1中展示了 Grounding DINO 1.5 系列的整体框架。该框架延续了原始 Grounding DINO 的双编码器-单解码器结构,并在此基础上扩展为 Grounding DINO 1.5 的两个版本:Pro 和 Edge,分别在下面介绍。
# 4.1.1 Grounding DINO 1.5 Pro
Grounding DINO 1.5 Pro 保留了原始 Grounding DINO 的核心架构,同时引入了更强大的视觉主干网络 Vision Transformer。我们采用了预训练的 ViT-L 模型作为主要视觉骨干网络,该模型在下游任务中表现优异,并且其纯 Transformer 结构为训练与推理过程的优化提供了坚实基础。
参考 Grounding DINO 和 GLIP 的方法,Grounding DINO 1.5 Pro 在特征提取过程中采用了深度早期融合(early fusion)策略。该策略通过图像与文本特征之间的交叉注意力机制,在解码阶段之前就融合信息,从而实现更紧密的模态融合。
我们还对早期融合与后期融合策略进行了比较:
- 早期融合通常带来更高的召回率和更精确的边框定位;
- 但也更容易出现幻觉(hallucination)现象,即检测出图中并不存在的目标;
- 后期融合仅在损失计算阶段整合图文信息,虽然能有效缓解幻觉问题,但会降低检测召回率,因为视觉与语言的特征对齐更具挑战性。
因此,为了同时提升模型的预测能力与推理时的稳健性,我们选择保留 early fusion 架构,并引入了更全面的训练采样策略,尤其提高了训练过程中的负样本比例。这些改进有助于在保持 early fusion 优势的同时,减轻其缺点,从而实现更优的性能平衡。
# 4.1.2 Grounding DINO 1.5 Edge
在众多应用中(如自动驾驶、医学图像处理、计算摄影等),将 Grounding DINO 部署于边缘设备是一项极具吸引力的需求。然而,开放集检测模型的计算成本与边缘设备的资源限制之间存在巨大差距。原始 Grounding DINO 模型使用多尺度图像特征和计算密集型的特征增强器(feature enhancer)以加速训练和提升性能,但这种设计难以满足实时应用场景的要求。
为了解决这一问题,我们提出了一种新颖的高效特征增强器(如图2所示)。考虑到低层图像特征缺乏语义信息且计算代价高(参考 Lite-DETR 的研究),我们将跨模态融合限定在高级图像特征(P5 层),从而大幅减少处理的 token 数量,显著降低了特征增强器的计算开销。
此外,为了方便在边缘 GPU 上部署,我们将原始的可变形自注意力(deformable self-attention)替换为普通自注意力(vanilla self-attention),并引入了一个跨尺度特征融合模块,将来自 P3 和 P4 层的低级图像特征进行整合。这样的设计有效平衡了特征增强能力与计算效率。
在这个面向边缘设备优化的 Grounding DINO 1.5 Edge 模型中,我们用新提出的高效特征增强器替换了原始模块,并采用了EfficientViT-L1 作为图像主干网络,实现了快速的多尺度特征提取。我们将模型部署在 NVIDIA Orin NX 平台上,在 640×640 输入尺寸下实现了超过 10 FPS 的推理速度。图 16 展示了模型在 NVIDIA Orin NX 上的预测可视化结果,充分验证了该模型在实际边缘计算环境中的有效性。
# 4.2 训练数据集
为了训练一个鲁棒的开放集目标检测模型,构建一个高质量、类别丰富、覆盖多种检测场景的 grounding 数据集至关重要。Grounding DINO 1.5 在一个包含超过 2000 万张图像的 grounding 数据集上进行了预训练,称为 Grounding-20M。这些图像均来自公开可用的数据源。我们精心设计了一套注释流程与后处理规则,以确保该数据集中的 grounding 注释具有高度的准确性与质量保障。