 Grounding+LLMs 模型汇总
Grounding+LLMs 模型汇总
按照大概的时间顺序总结了一下 LLM 做 grounding 任务的模型的创新点和主要思路。
# 1.1. Shikra
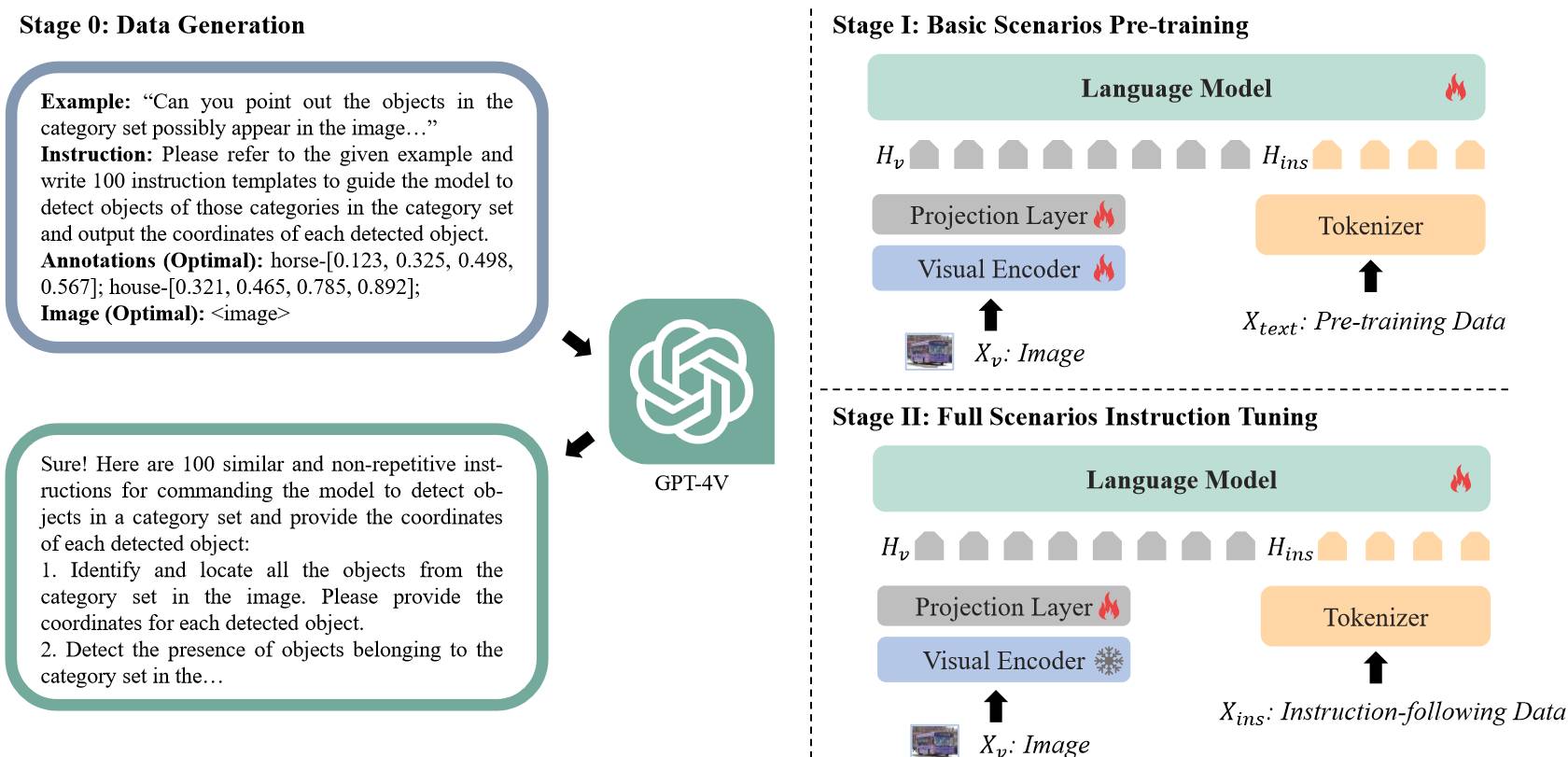
它使得多模态大模型在对话时有指代物体的能力。论文没给模型框架图(其实和下面的 KOSMOS-2 差不多),大模型用的 Vicuna,视觉编码器用的 ViT。使用[xmin, ymin, xmax, ymax]表示 bounding box,使用[xcenter, ycenter]表示物体中心。使用 GPT-4 生成训练数据,训练数据如下图。

# 1.2. KOSMOS-2
目的和 Shikra 差不多,让模型有能够理解指代物体的能力。<loc44> = (x 1, y 2), <loc863> = (x 2, y 2)。设计了一个构造数据的方法,构造了大规模数据集 grounded image-text pairs (called GRIT)。

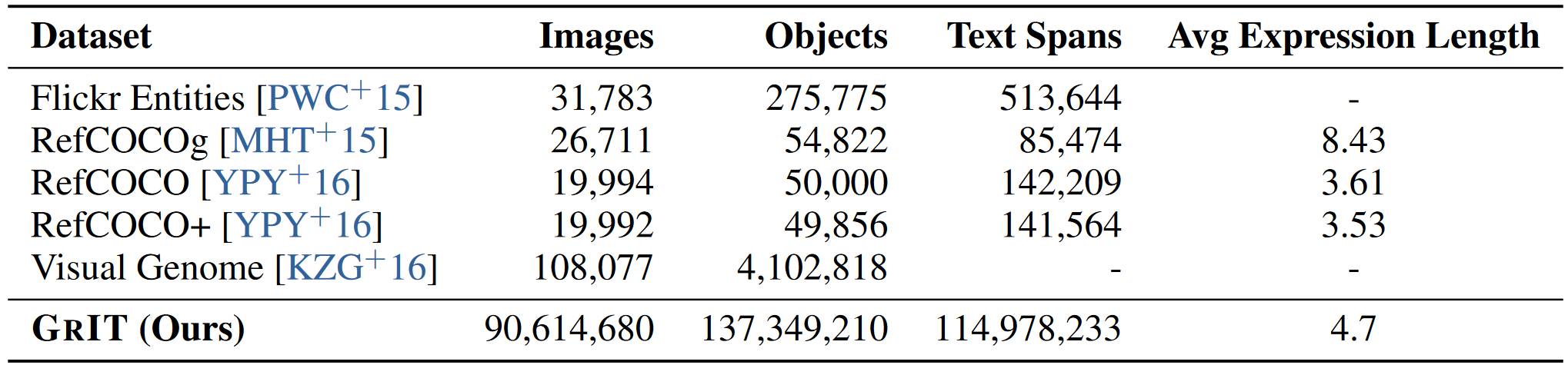
# 1.3. BuboGPT
相比上面模型,BuboGPT 能够同时理解 text-image-audio,结构没啥变化,就增加了一个模态。
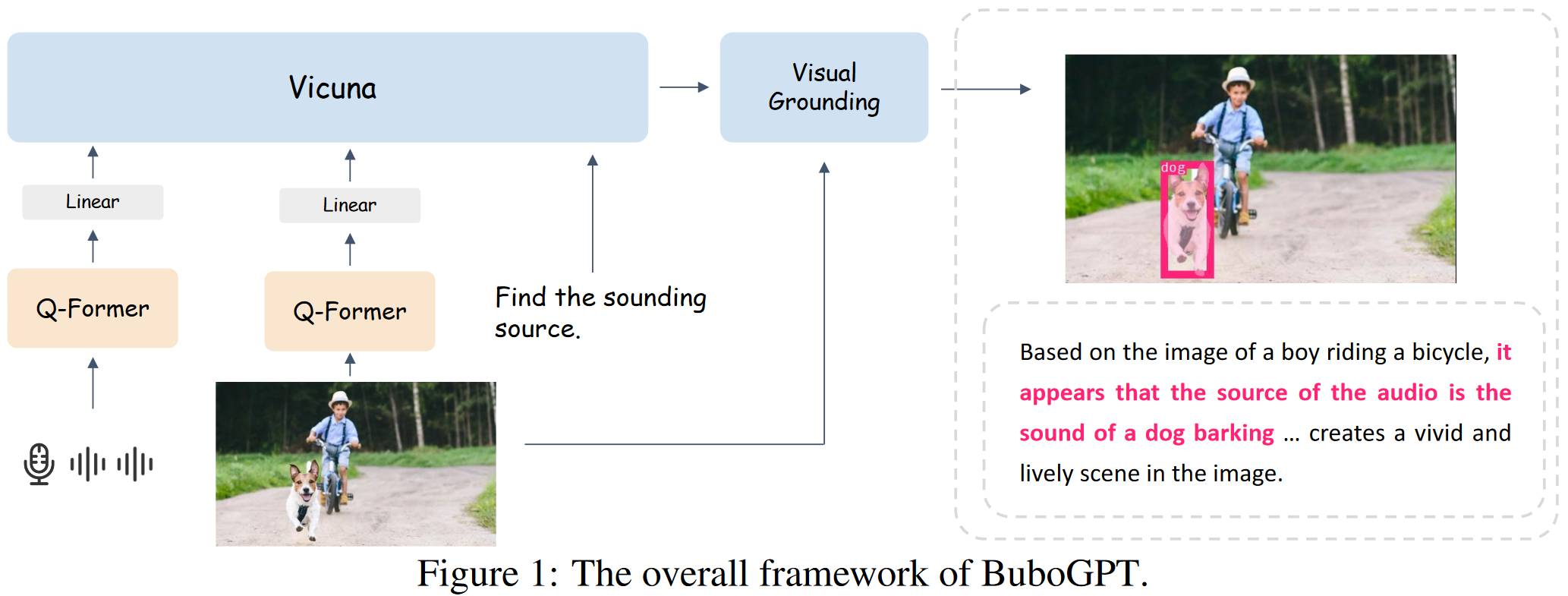
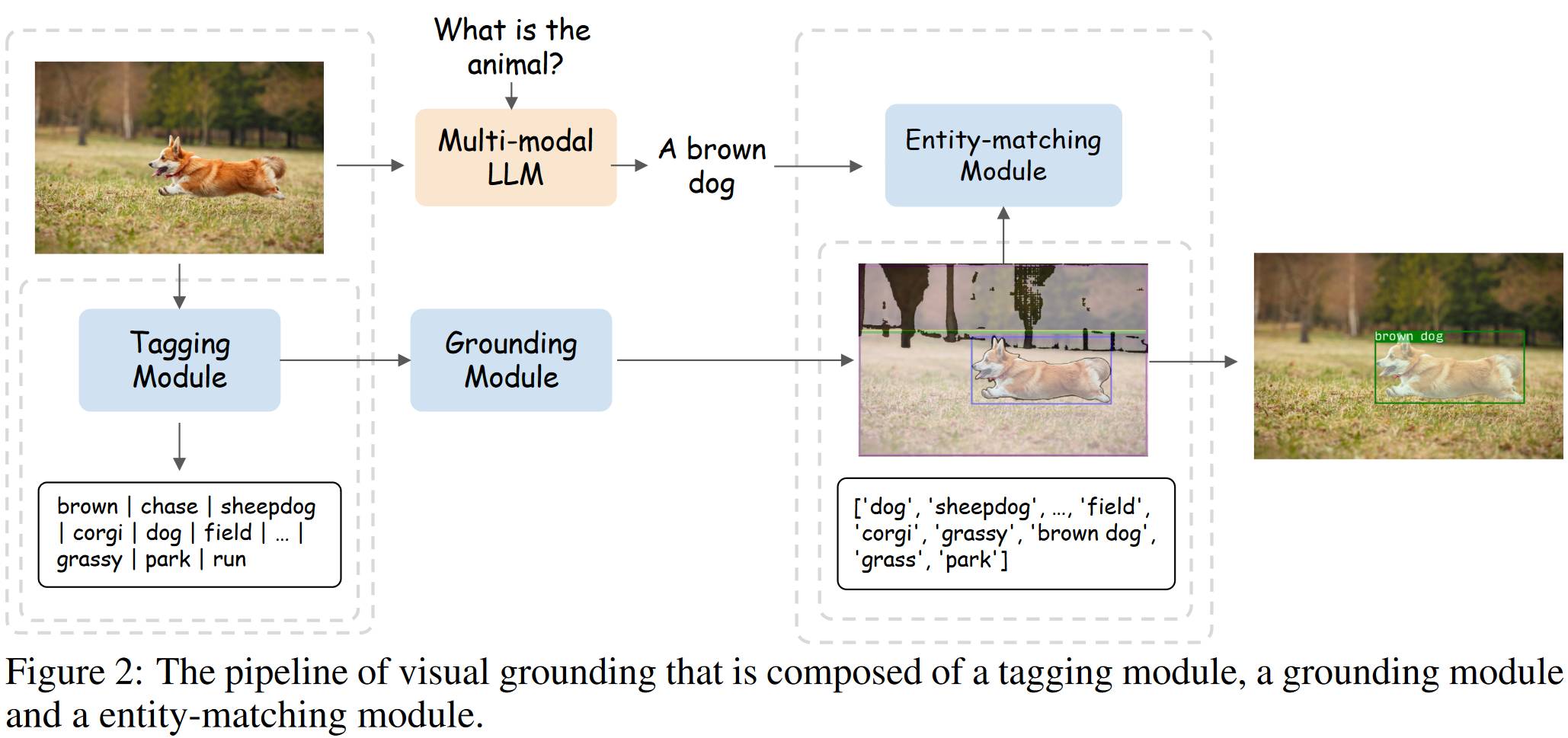
# 1.4. Ferret
Ferret 相比其他模型升级的地方是,它可以接受图像层面的任何形状的空间指示(如 point,box,free-form shape),之前的方法都只能在语言层面指示。他提出 spatial-aware visual sampler 就是用来处理这个的。
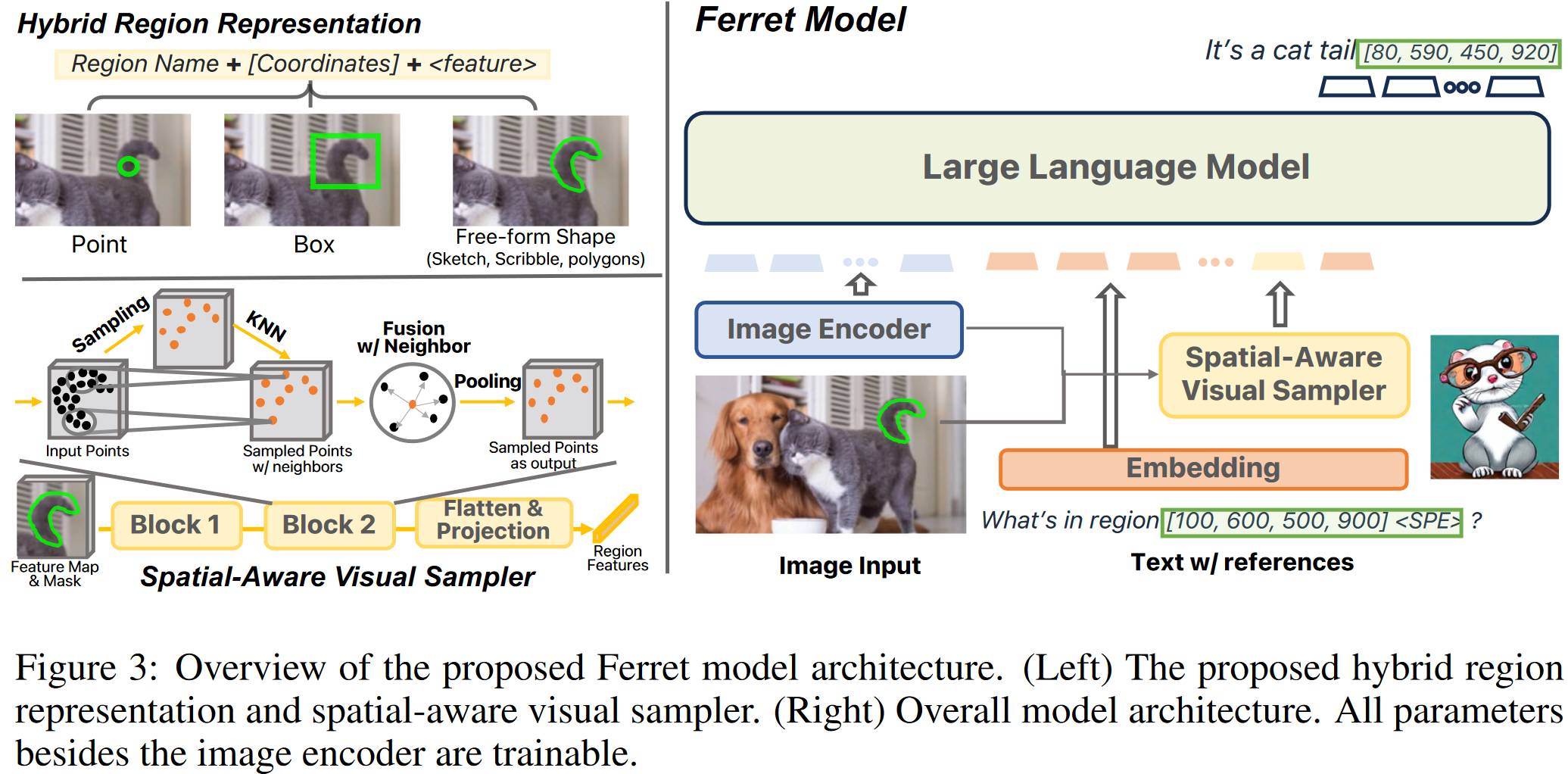
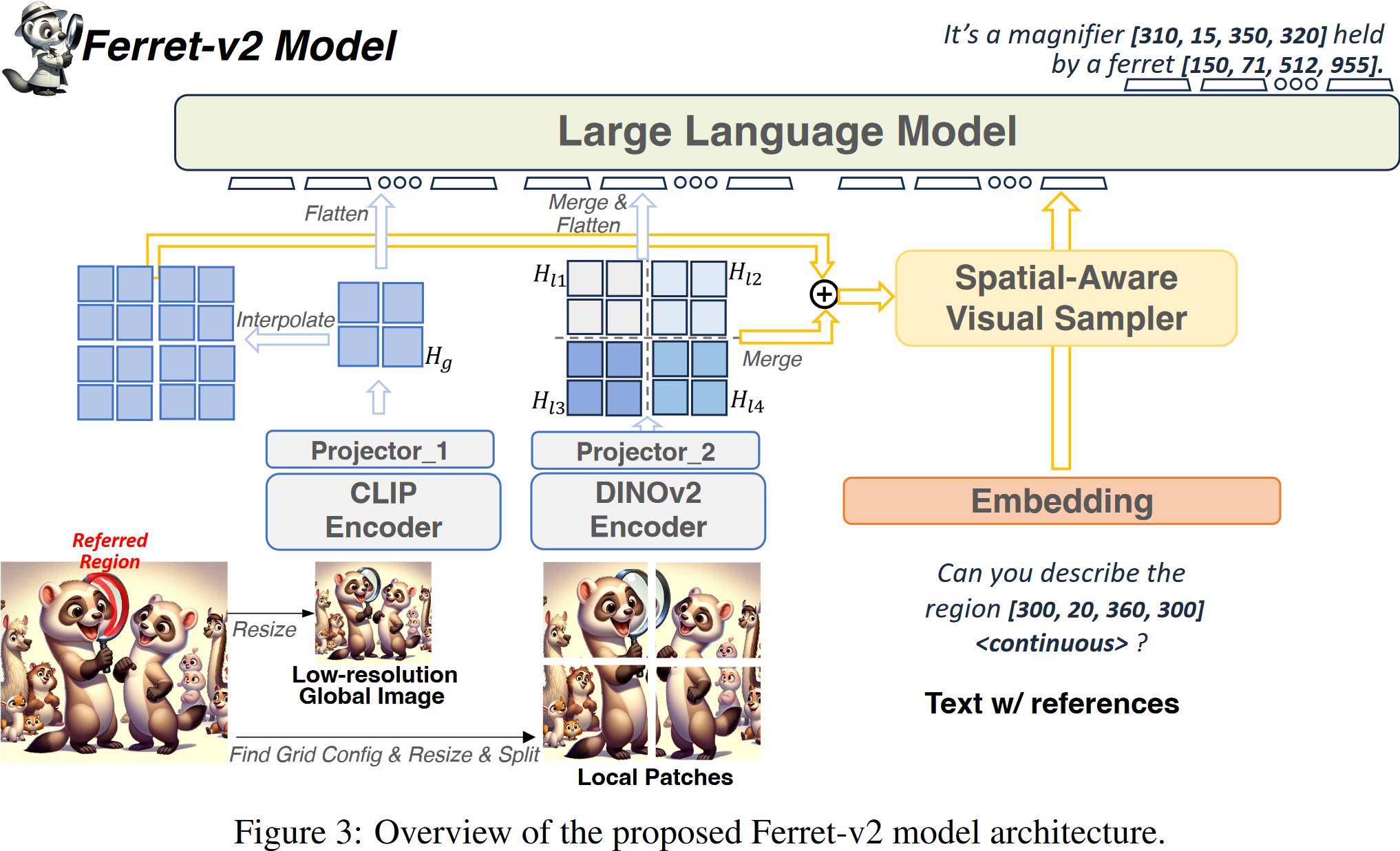
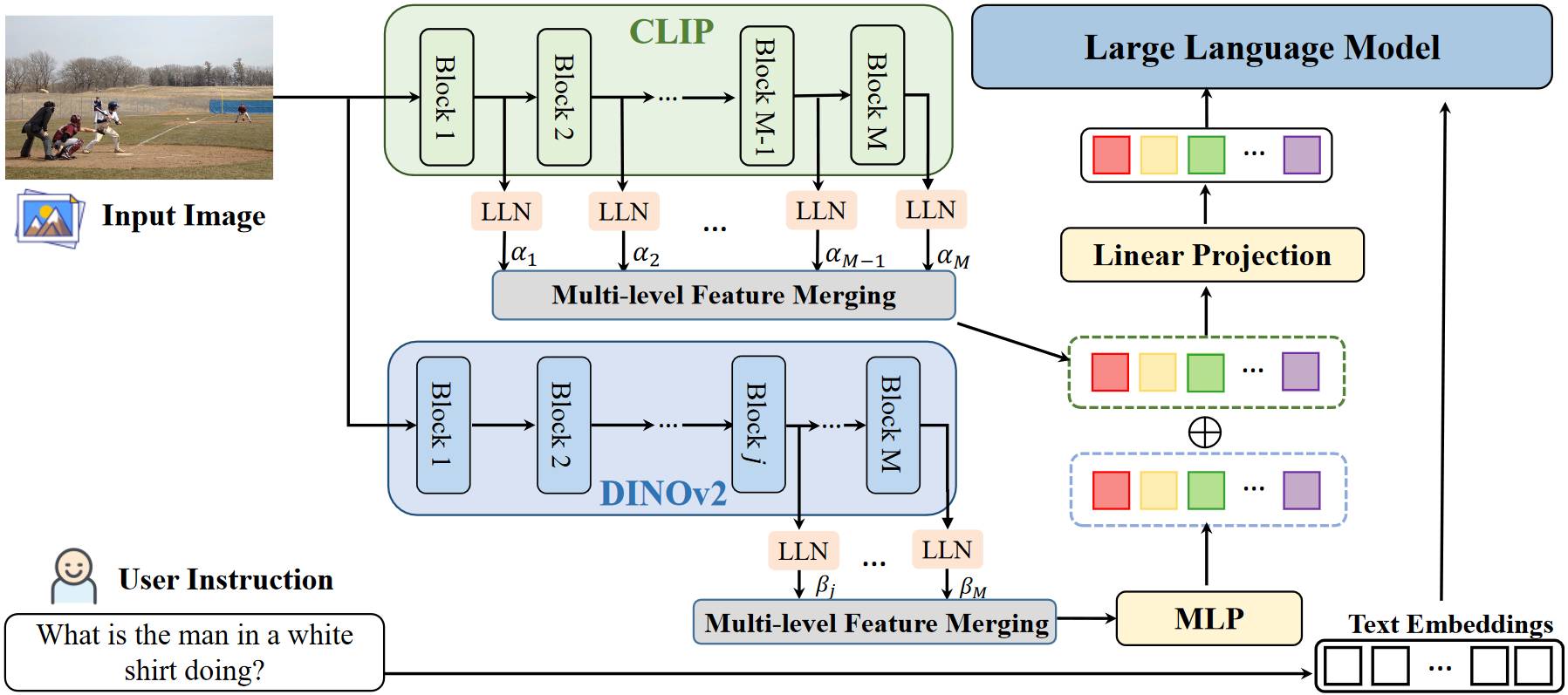
# 1.5. Ferret v 2
相比于 v 1, Ferret v 2 能够处理高分辨率的图像,低分辨率图像经过 CLIP,引入了一个额外的 DINOv 2 编码器来处理高分辨图像。
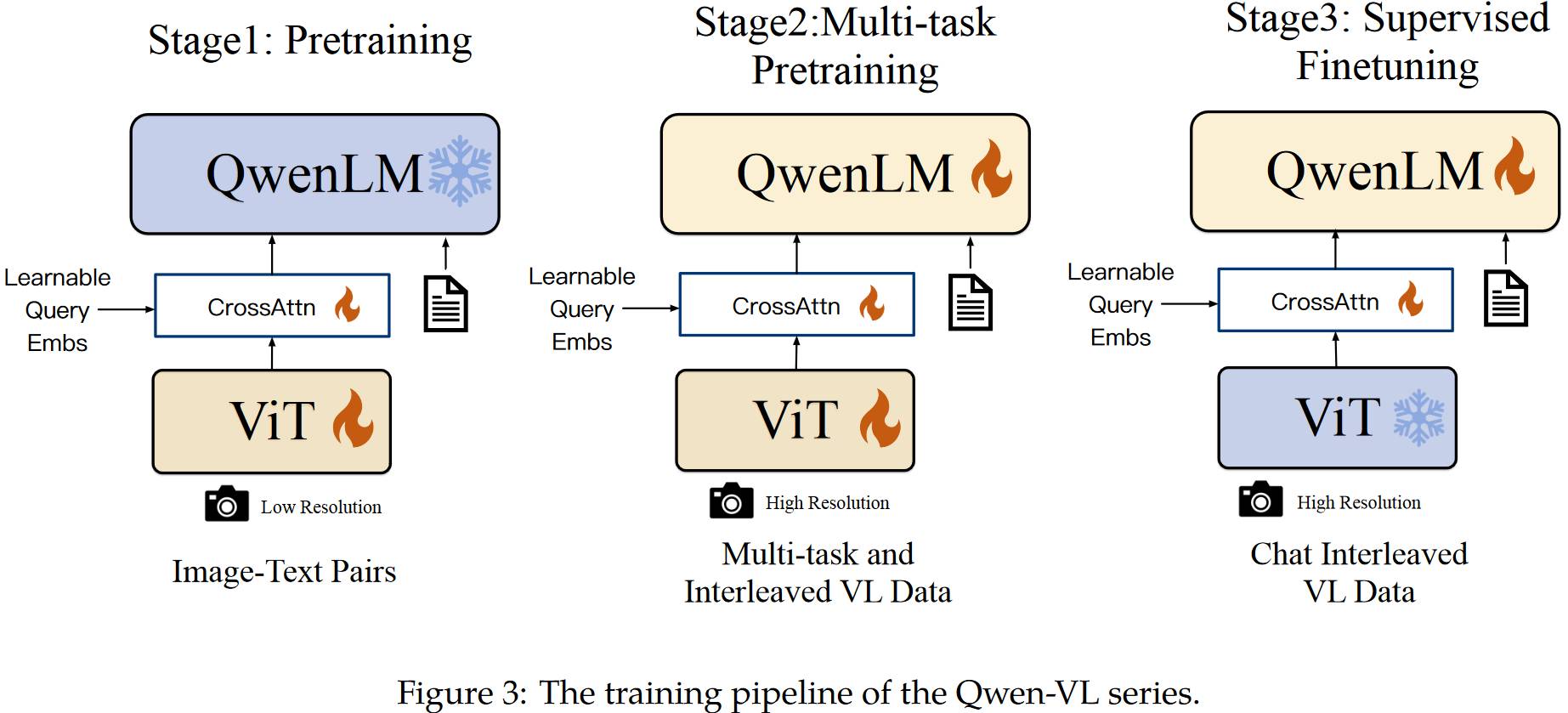
# 1.6. Qwen-VL
从下图可以看出,和之前的模型差不多。就多了个 Vision-Language Adapter,就是图中的 CrossAttn,可学习 embs 作为 query,图像特征作为 key 和 value。所以送入 LLM 不是图像图像特征了而是可学习 embs。
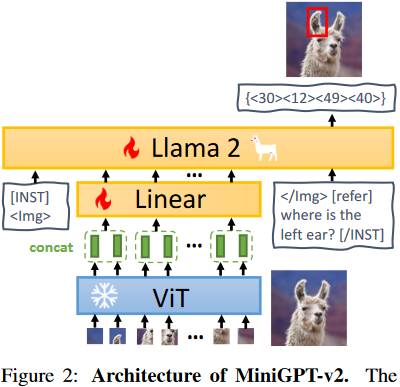
# 1.7. MiniGPT-v 2
从下面的模型结构可以看出,MiniGPT-v 2 和其他模型区别不大。一个不同的地方就是它引入了一个 Identifiers,不同任务的 Identifiers 是不同的(如下图中的[refer]就表示要做 REC 任务)。

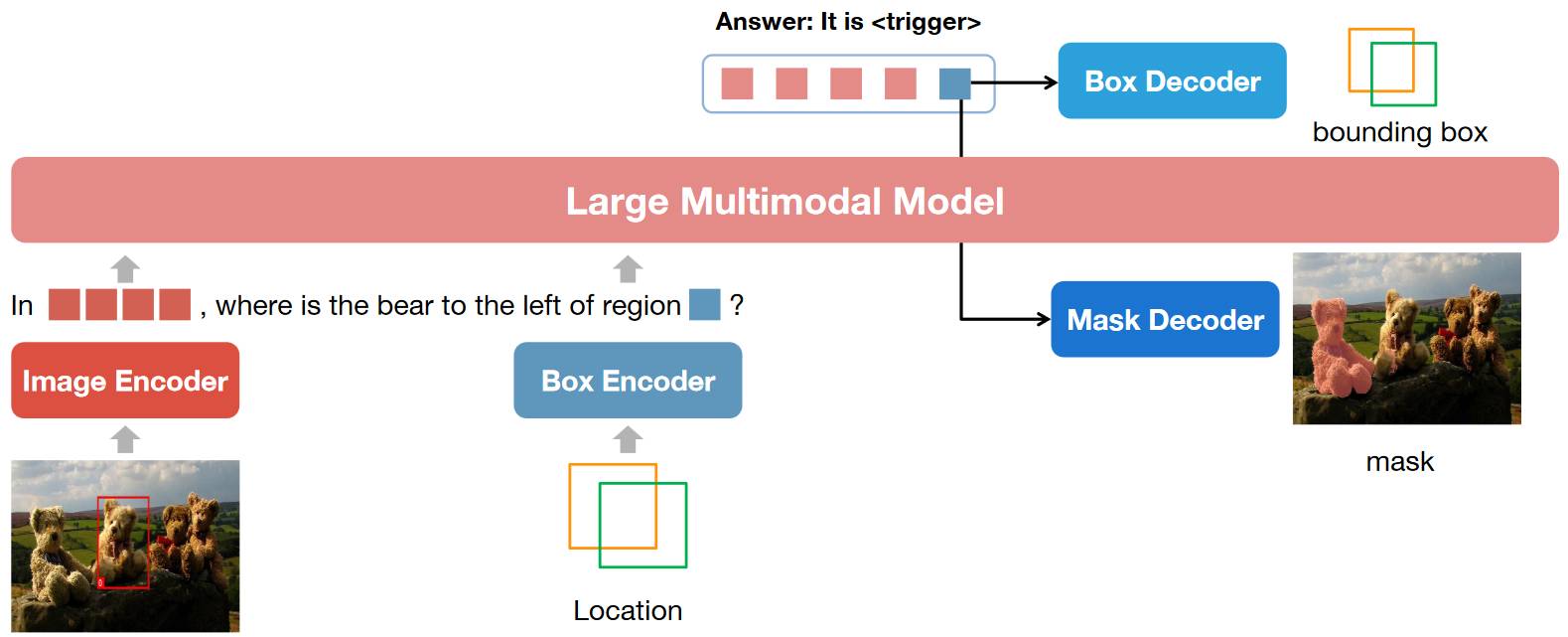
# 1.8. NExT-Chat
NExT-Chat 和其他模型不同的是,其它模型直接将坐标[xmin, ymin, xmax, ymax]作为语言送入 LLM,NExT-Chat 就先对坐标进行编码(Box Encoder)然后送入大模型,Box Encoder 是 2 层 MLP。
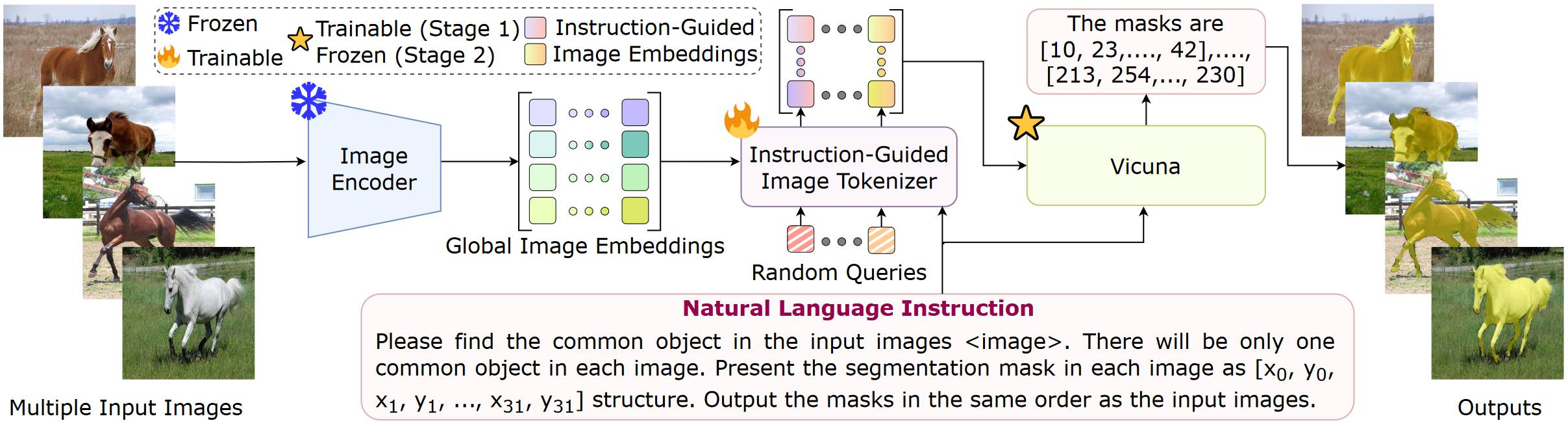
# 1.9. VistaLLM
VistaLLM 和其他模型不同的地方是,VistaLLM 提出了一个 Instruction-guided Image Tokenizer(其实是一个 QFormer)来使得图像特征和指令进行对齐。
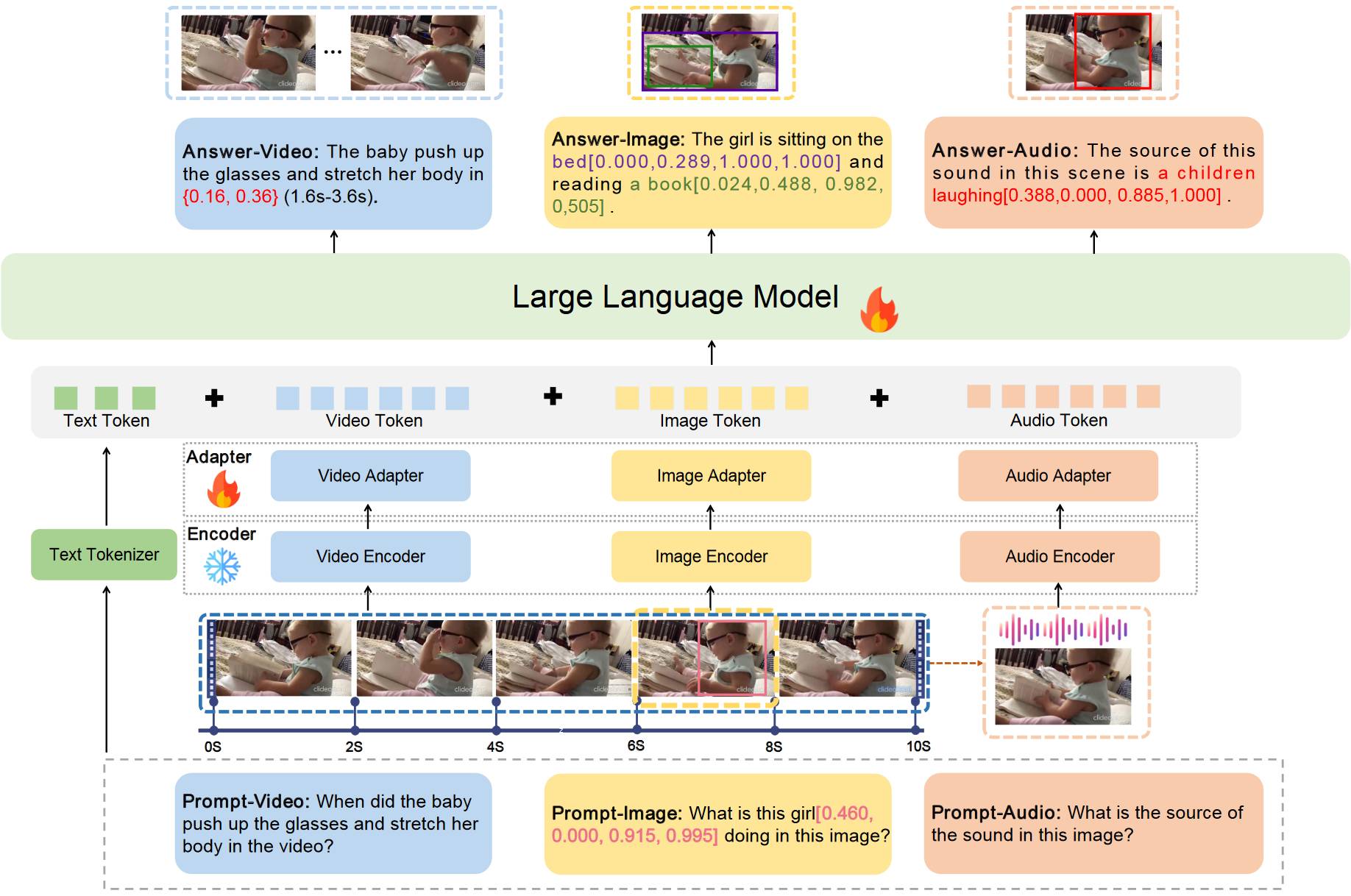
# 1.10. GroundingGPT
GroundingGPT 模型结构和正常方法没什么区别。就增加了一个对视频的理解。GroundingGPT 可以理解 Image-Video-Audio-Text。
# 1.11. COMM
从下图可以看出 COMM 其实就是使用了 2 个图像特征编码器(CLIP 和)提取视觉特征,然后再把他们 concat 起来。
# 1.12. Griffon
Griffon 在模型与正常的方法没有什么区别。但他提出了一个数据集,包含 600 万的训练数据。
# 1.13. Griffon v 2
Griffon v 2 主要解决的高分辨率图像(1024 x 1024)的问题。高分辨图像的问题是视觉 token 太多了,计算复杂度高。Griffon v 2 其实就是在 high-resolution visual encoder(其实就是 ViT)后接上卷积层。然后他也能接受除文本之外的 prompt 了,如下图的图片。
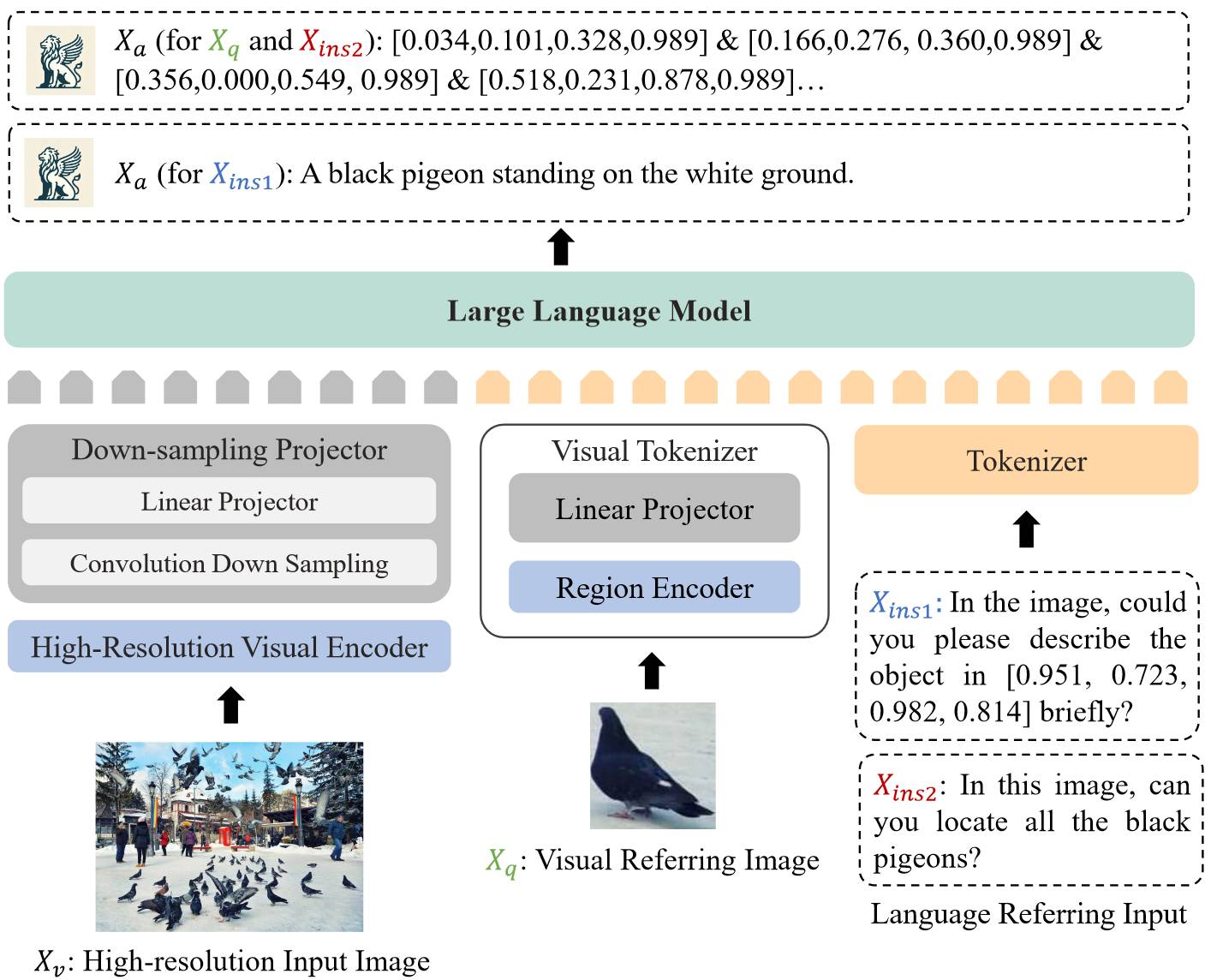
# 1.14. Groma
Groma 和其他模型主要的不同是,Groma 除了将全局的图像特征送入 LLM,还会使用一个 Region Proposer 生成一些 region proposal(bounding box),将这些 proposal 送入 Region Encoder 得到局部的视觉特征,然后送入 LLM。
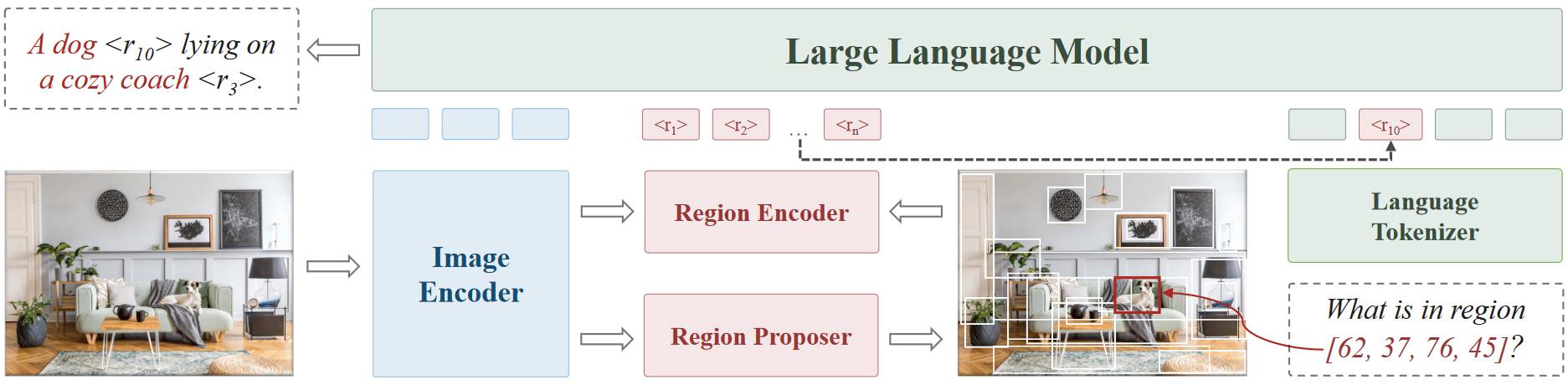
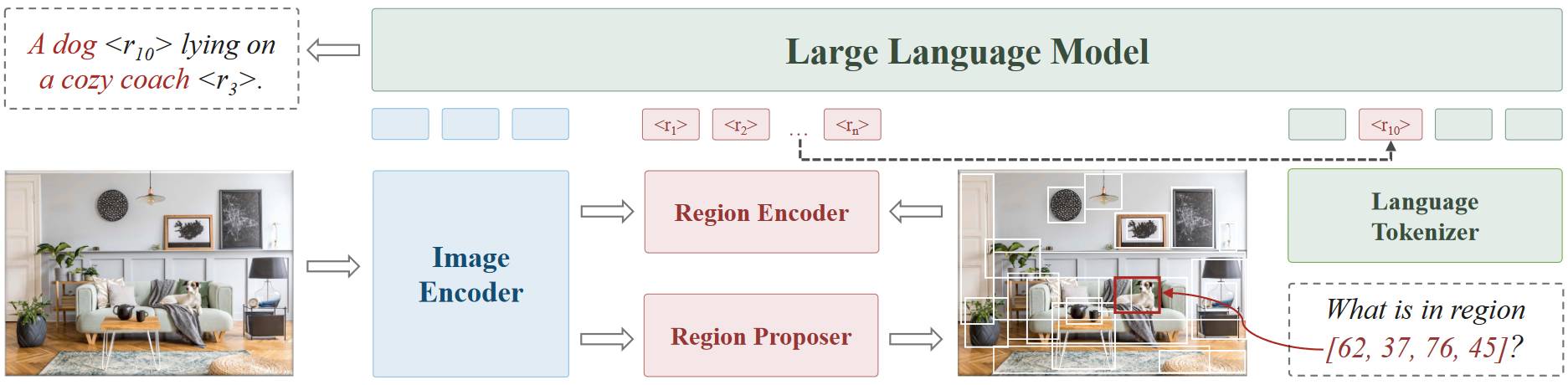
# 1.15. GLaMM
GLaMM 是一个能接受视觉 prompt 的一个模型,靠的是 Region Encoder 生成局部区域的特征。Grounding Image Encoder 其实就是 SAM 的图像编码器,Pixel Decoder 其实就是类 SAM 的解码器。
# 1.16. SPHINX
SPHINX 和其他模型的不同主要是 Mixed Visual Encoders,它包括了 4 种编码器,CLIP-ConvNeXt,CLIP-ViT,DINOv 2-ViT,Q-Former。使用这 4 种编码器来提取特征。
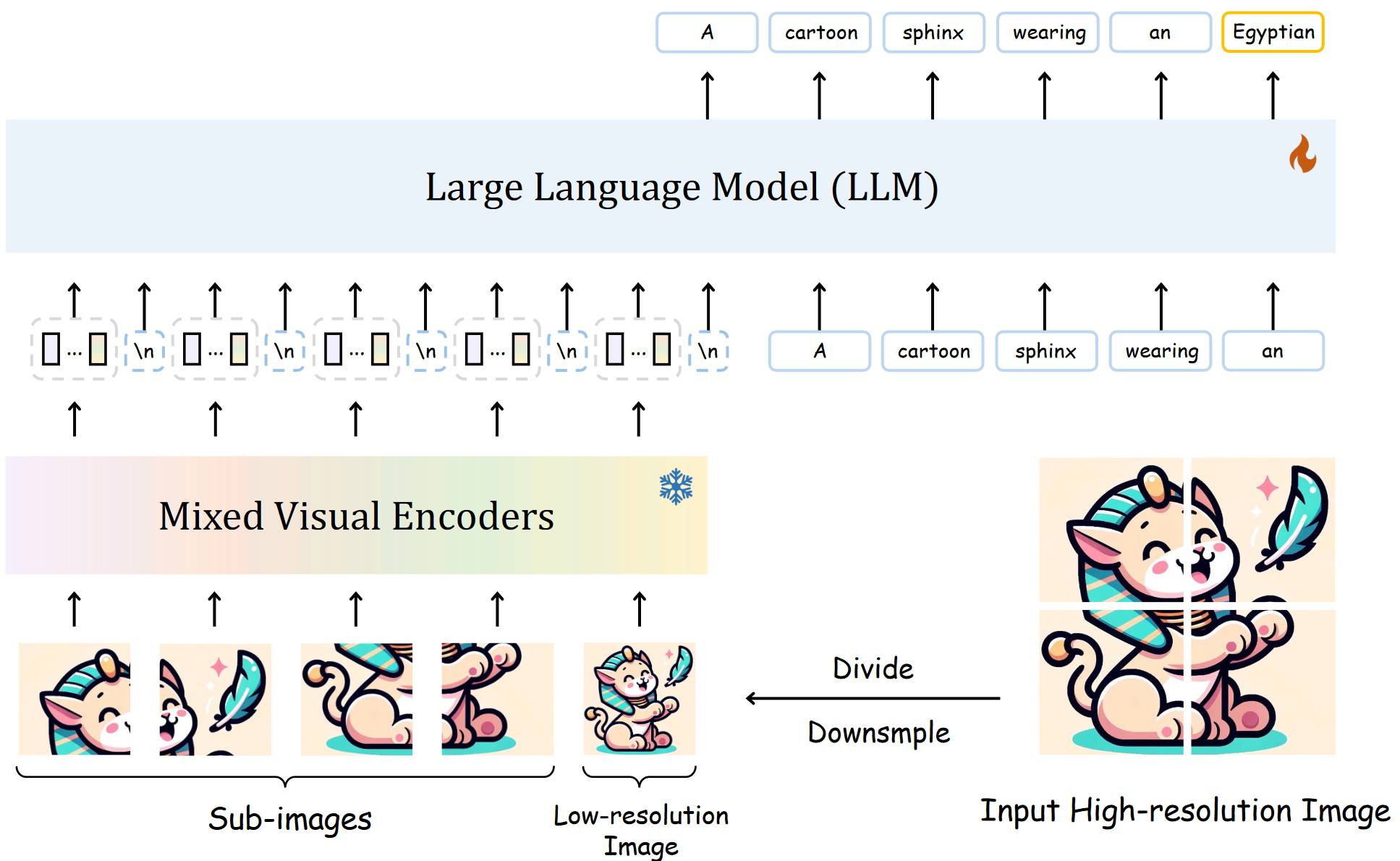
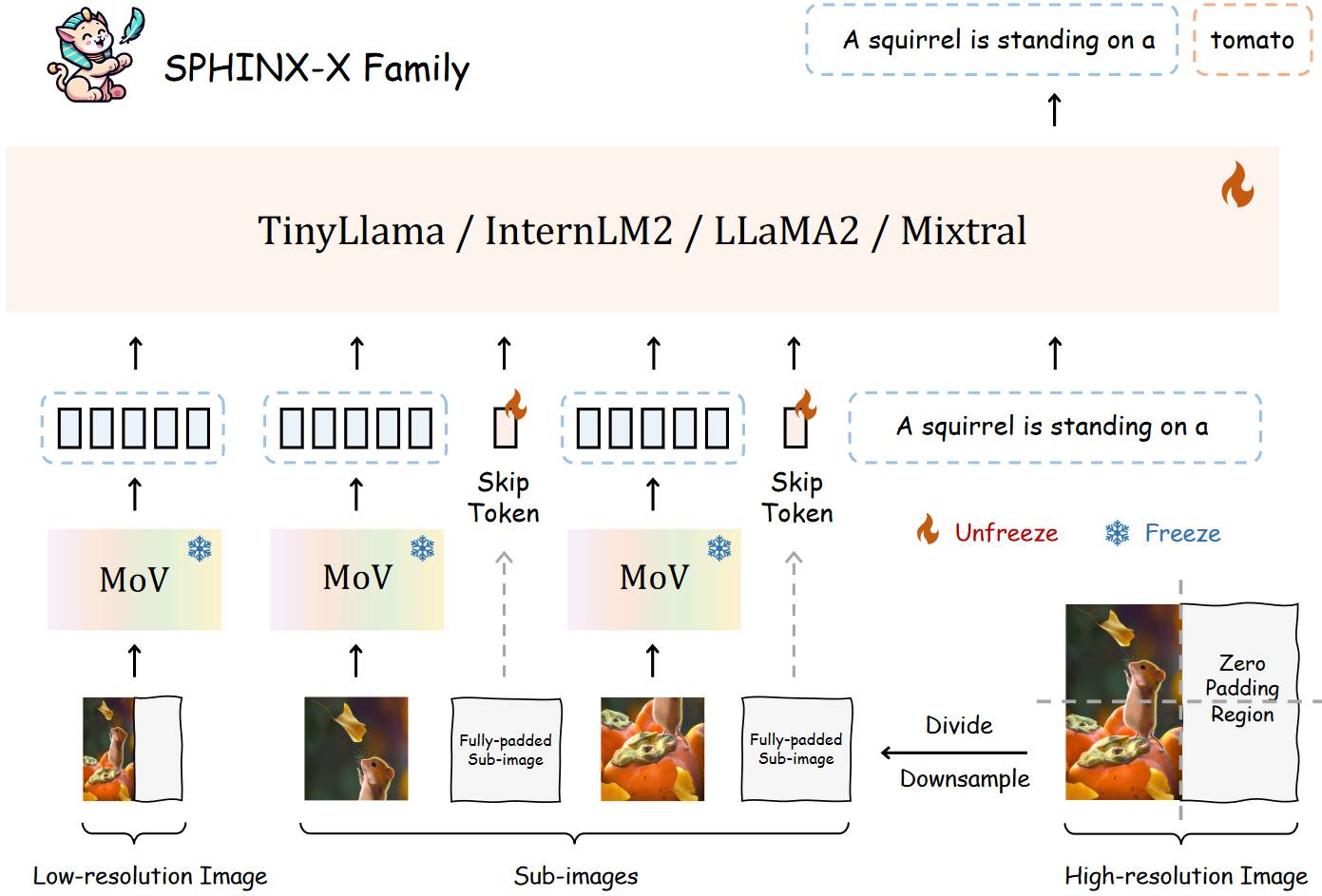
# 1.17. SPHINX-X
相比 SPHINX,SPHINX-X 在处理高分辨率图像,SPHINX-X 考虑了图片可能有填充的情况,它为填充的子图像增加了 Skip Token。MoV 其实就是使用了两种图像编码器。
← DINO-X