 所有权
所有权
# 什么是所有权?
所有权是一种用于确保 Rust 程序安全的机制。要理解所有权,我们首先需要明白是什么让 Rust 程序变得安全(或不安全)。
# 安全即无未定义行为
让我们从一个例子开始。这个程序是安全的:
fn read(y: bool) {
if y {
println!("y is true!");
}
}
fn main() {
let x = true;
read(x);
}
2
3
4
5
6
7
8
9
10
我们可以通过把对 read 的调用移到 x 的定义之前,使这个程序变得不安全:
注意:在本章中,我们会使用许多无法编译的代码示例。如果你不确定某个程序是否应该编译成功,请留意带有问号的螃蟹标志。
第二个程序之所以不安全,是因为 read(x) 期望 x 已经有一个 bool 类型的值,但实际上 x 还没有被赋值。
如果这样的程序由解释器执行,那么在 x 被定义之前读取它会抛出异常,比如 Python 的 NameError 或 Javascript 的 ReferenceError。但抛出异常是有代价的:每次解释型程序读取变量时,解释器都必须检查该变量是否已经定义。
Rust 的目标是将程序编译成高效的二进制文件,尽量减少运行时检查。因此,Rust 在运行时不会检查变量在使用前是否已定义,而是在编译时进行检查。如果你尝试编译这个不安全的程序,你会收到这样的错误:
error[E0425]: cannot find value `x` in this scope
--> src/main.rs:8:10
|
8 | read(x); // oh no! x isn't defined!
| ^ not found in this scope
2
3
4
5
6
你可能直觉上认为,Rust 保证变量在使用前已被定义是件好事。但为什么呢?要解释这条规则,我们需要问:如果 Rust 允许这些被拒绝的程序通过编译,会发生什么?
我们先来看一下安全程序是如何编译和执行的。在采用 x86 架构处理器的计算机上,Rust 为安全程序的 main 函数生成了如下汇编代码(完整的汇编代码可在此处查看):
main:
; ...
mov edi, 1
call read
; ...
2
3
4
5
注意:如果你不熟悉汇编代码也没关系!本节只包含一些汇编示例,目的是让你了解 Rust 底层是如何工作的。理解 Rust 并不需要掌握汇编。
这段汇编代码会做以下几件事:
- 将数字 1(代表 true)存入名为 edi 的寄存器(一种汇编变量)。
- 调用
read函数,read期望它的第一个参数 y 存在于 edi 寄存器中。
如果那个不安全的函数被允许编译,那么它的汇编代码可能是这样的:
main:
; ...
call read
mov edi, 1 ; mov is after call
; ...
2
3
4
5
这个程序是不安全的,因为 read 会期望 edi 是一个布尔值,也就是数字 0 或 1。但实际上,edi 可能是任何值:2、100、0x1337BEEF 等。当 read 想用它的参数 y 做任何操作时,都会立刻导致未定义行为(UNDEFINED BEHAVIOR)!
Rust 并没有规定当你运行 if y { .. } 时,如果 y 不是 true 或 false 会发生什么。这种行为,或者说执行那条指令后的结果,就是未定义行为。结果可能包括,例如:
- 代码正常执行,没有崩溃,也没人发现有问题。
- 代码立刻因段错误(segmentation fault)或其它操作系统错误而崩溃。
- 代码表面上正常执行,直到某个恶意用户制造出特定输入,进而删除你的生产数据库、覆盖你的备份,甚至偷走你的午餐钱。
Rust 的一个根本目标,就是确保你的程序永远不会出现未定义行为。这就是“安全性”的含义。未定义行为对于拥有直接内存访问的底层程序来说尤其危险。大约 70% 的底层系统安全漏洞都是由内存损坏引起的,而内存损坏正是一种未定义行为。
Rust 的另一个目标,是在编译时而不是运行时阻止未定义行为。这个目标有两个动机:
- 在编译时发现 bug,意味着可以避免这些 bug 出现在生产环境中,提高软件的可靠性。
- 在编译时发现 bug,也意味着运行时几乎不需要为这些 bug 进行检查,从而提升软件性能。
当然,Rust 并不能阻止所有的 bug。如果一个应用暴露了一个公开且无需认证的 /delete-production-database 接口,恶意用户不需要依赖某个可疑的 if 语句就能删掉数据库。但相比于那些保护措施更少的语言(比如 Google Android 团队曾经发现的情况),Rust 的保护机制依然能让程序更安全。
# 所有权:作为内存安全的约束机制
既然安全意味着没有未定义行为,而所有权又关乎安全,那么我们需要从所有权能够防止哪些未定义行为的角度来理解它。《Rust 参考手册》列出了大量被认为是“未定义行为”的情况。目前我们只关注其中的一类:对内存的操作。
内存是程序执行过程中存储数据的空间。关于内存,有很多种理解方式:
- 如果你不熟悉系统编程,你可能会把内存看作“我电脑里的 RAM”或“如果加载太多数据就会用完的东西”这样的高层概念。
- 如果你熟悉系统编程,你可能会把内存看作“字节数组”或者“我用 malloc 得到的指针”这样的低层概念。
这两种内存模型都是合理的,但都不足以解释 Rust 的工作方式。高层模型过于抽象,无法解释 Rust 的原理,比如你需要理解什么是指针。低层模型又过于具体,Rust 其实并不允许你把内存当成字节数组来解释。
Rust 提供了一种特殊的内存模型。所有权就是在这种内存观念下安全使用内存的一种约束机制。本章剩下的内容会详细介绍 Rust 的内存模型。
# 变量存储在栈上
下面是一个类似于你在第 3.3 节看到的程序:它定义了一个数字 n,并将 n 作为参数调用了函数 plus_one。在程序下方,是一种新的图示方式。这个图展示了在程序执行过程中三个标记点上,内存的内容是如何变化的。
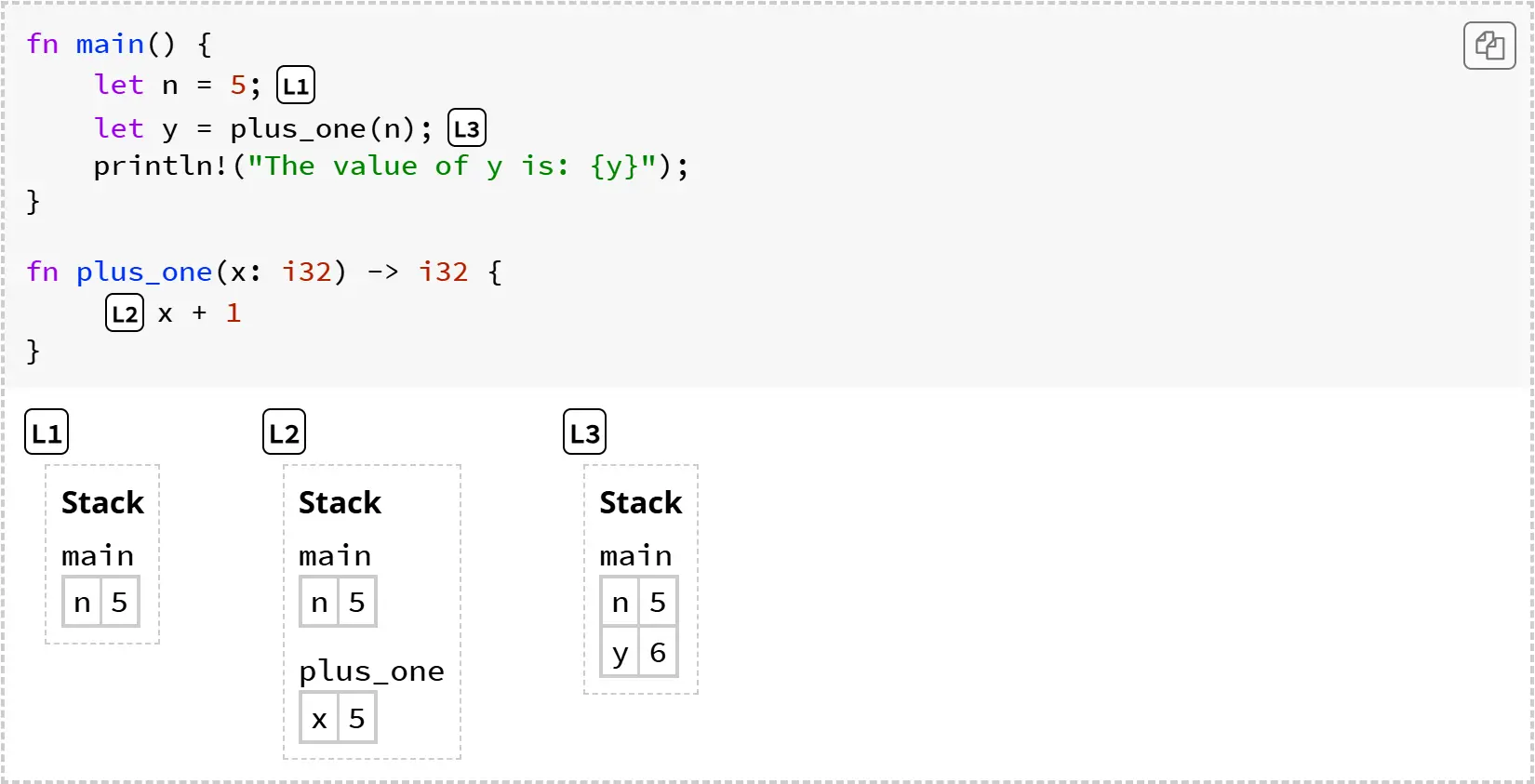
变量存在于栈帧中。栈帧(frame)是变量与其值在某个作用域(如一个函数)内的映射关系。例如:
- 在位置 L1,
main的帧中保存着n = 5。 - 在位置 L2,
plus_one的帧中保存着x = 5。 - 在位置 L3,
main的帧中保存着n = 5和y = 6。
栈帧按当前调用的函数顺序,组成一个“栈”(stack)。比如,在 L2 时,main 的帧在被调用的 plus_one 的帧之下。当函数返回时,Rust 会释放该函数的帧(这种释放也叫做“free”或“drop”,这些词可以互换使用)。帧的这一系列操作被称为“栈”,因为最新加入的帧总是最先被释放的。
注意:这个内存模型并不能完全描述 Rust 实际的运行方式!正如前面汇编代码所展示的,Rust 编译器有时会把
n或x存到寄存器而不是栈帧中。但这种差异只是实现细节,不会影响你对 Rust 安全机制的理解,所以我们可以只关注变量全部存储在帧中的简单情况。
当表达式读取一个变量时,该变量的值会从栈帧的槽位中被复制出来。例如,如果我们运行下面的程序:
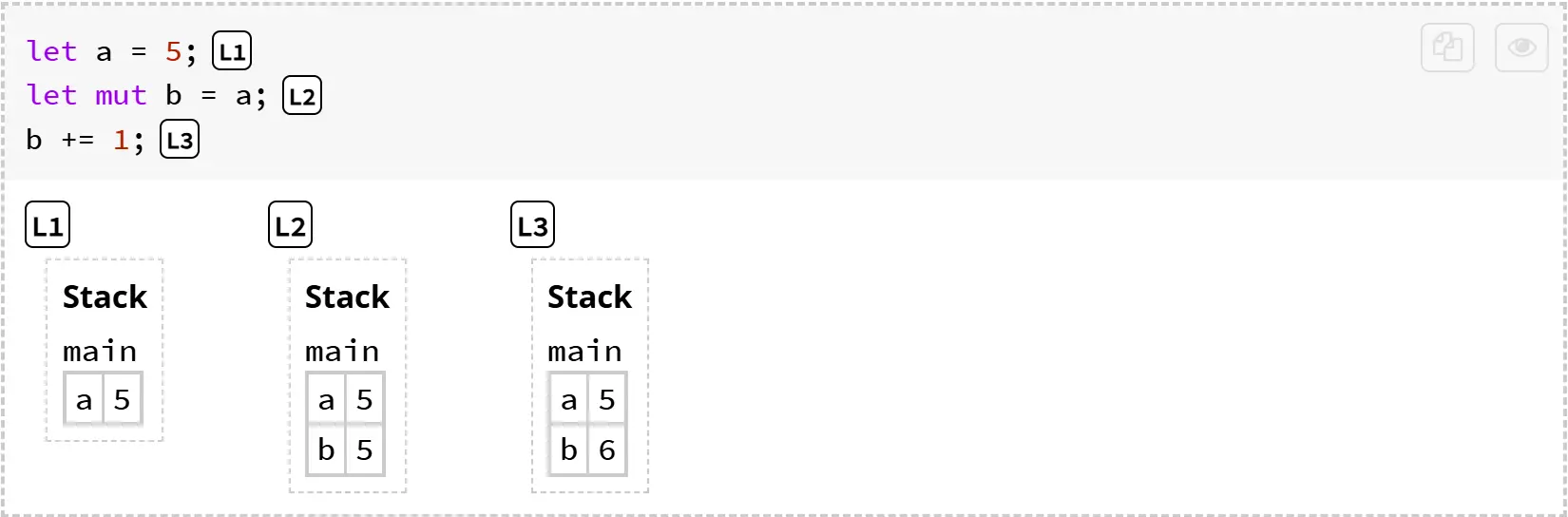
变量 a 的值会被复制到 b,即使之后修改了 b,a 也不会受到影响。
# Box 类型的值存储在堆上
然而,复制数据可能会占用大量内存。例如,来看一个略有不同的程序。这个程序会复制一个包含一百万个元素的数组:
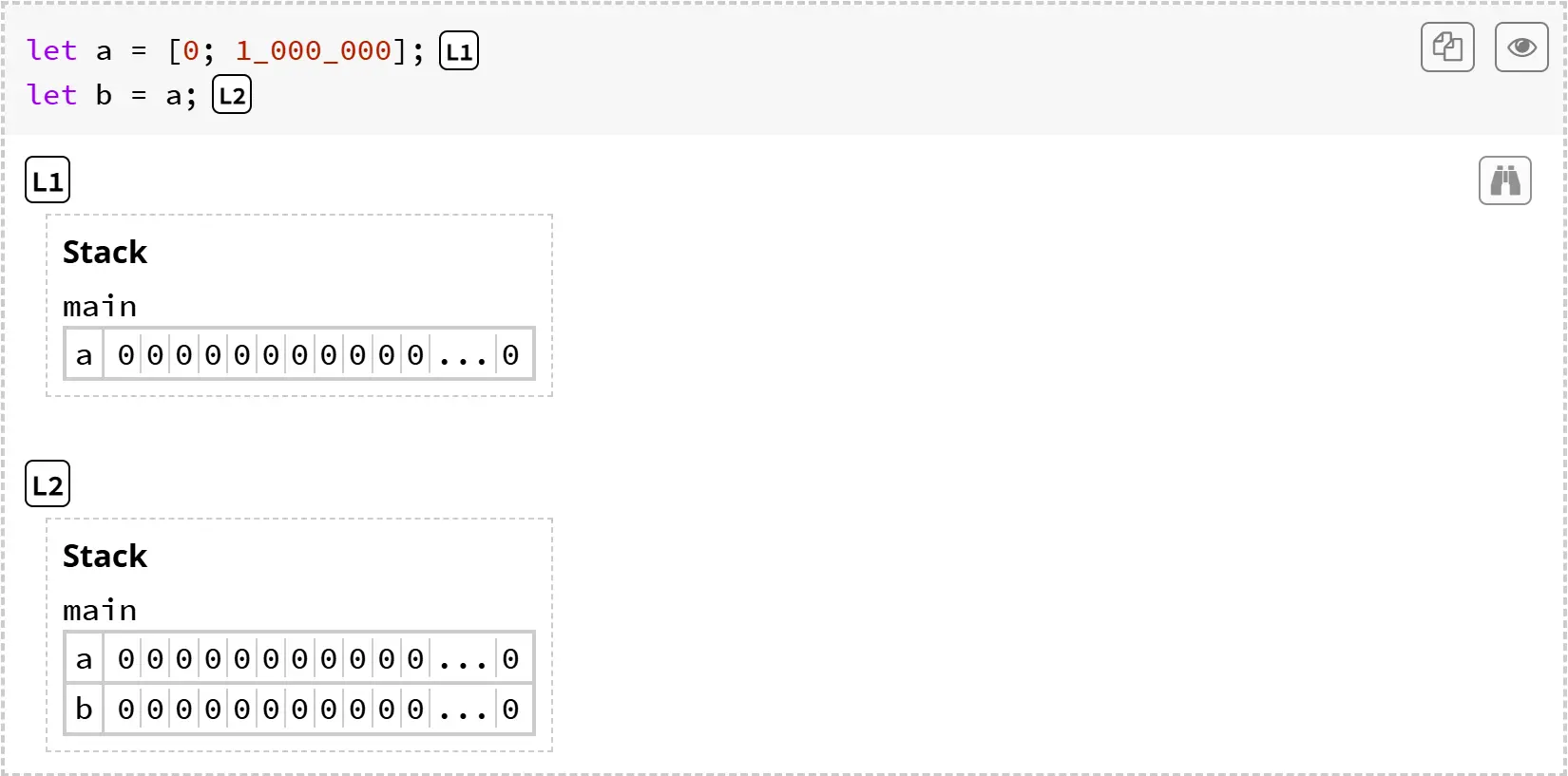
注意,将 a 复制到 b 后,main 的帧里就有了 200 万个元素。
为了在不复制数据的情况下转移对数据的访问权,Rust 使用了指针。指针是一种描述内存位置的值,指针指向的那个值叫做 pointee(被指对象)。最常见的创建指针的方法之一就是在堆(heap)上分配内存。堆是一个独立的内存区域,数据可以在其中长时间存活,并且不依赖于某个特定的栈帧。Rust 提供了一种叫做 Box 的类型,用于把数据放到堆上。例如,我们可以用 Box::new 把这个包含一百万个元素的数组包装起来,如下所示:
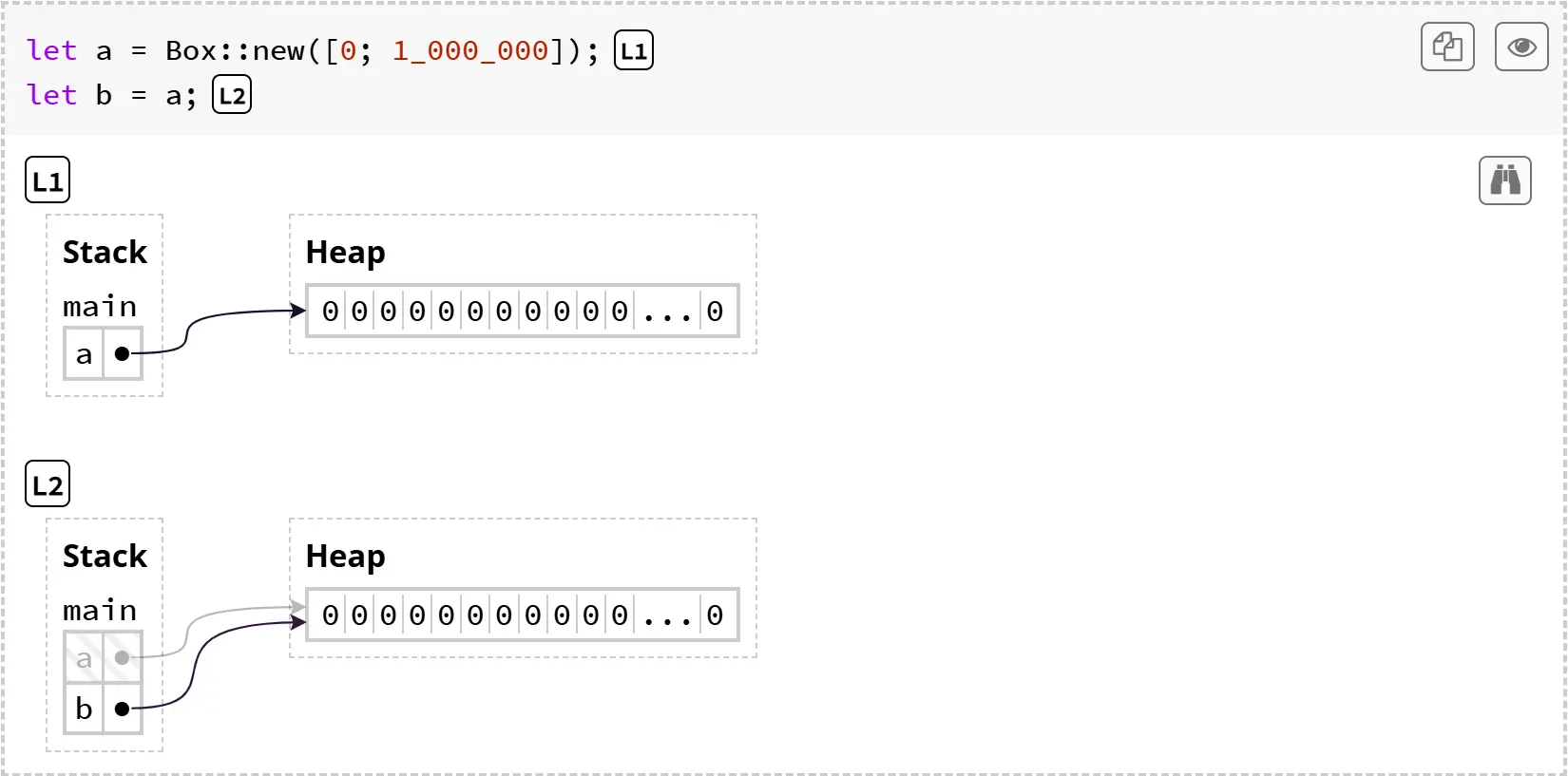
注意,现在任何时刻内存中都只有一份数组。在 L1,变量 a 的值是一个指向堆中数组的指针(图中用带箭头的点表示)。语句 let b = a 把 a 的指针复制给了 b,但指针所指向的数据本身并没有被复制。需要注意的是,a 现在被灰色显示,因为它已经被“移动”了——至于这意味着什么,我们很快就会讲到。
# Rust 不允许手动管理内存
内存管理指的是分配内存和释放内存的过程。换句话说,就是找到未被使用的内存,并在不再需要时归还那部分内存。栈帧的管理由 Rust 自动完成。当调用一个函数时,Rust 会为被调用的函数分配一个栈帧;当函数调用结束时,Rust 会释放这个栈帧。
正如上文所说,堆上的数据是在调用 Box::new(..) 时分配的。那么,堆上的数据又是什么时候被释放的呢?假设 Rust 提供了一个 free() 函数,可以手动释放堆分配的内存,并且允许程序员随时调用 free()。这种“手动”内存管理方式很容易引发 bug。例如,我们可能会读取一个已经被释放的指针:
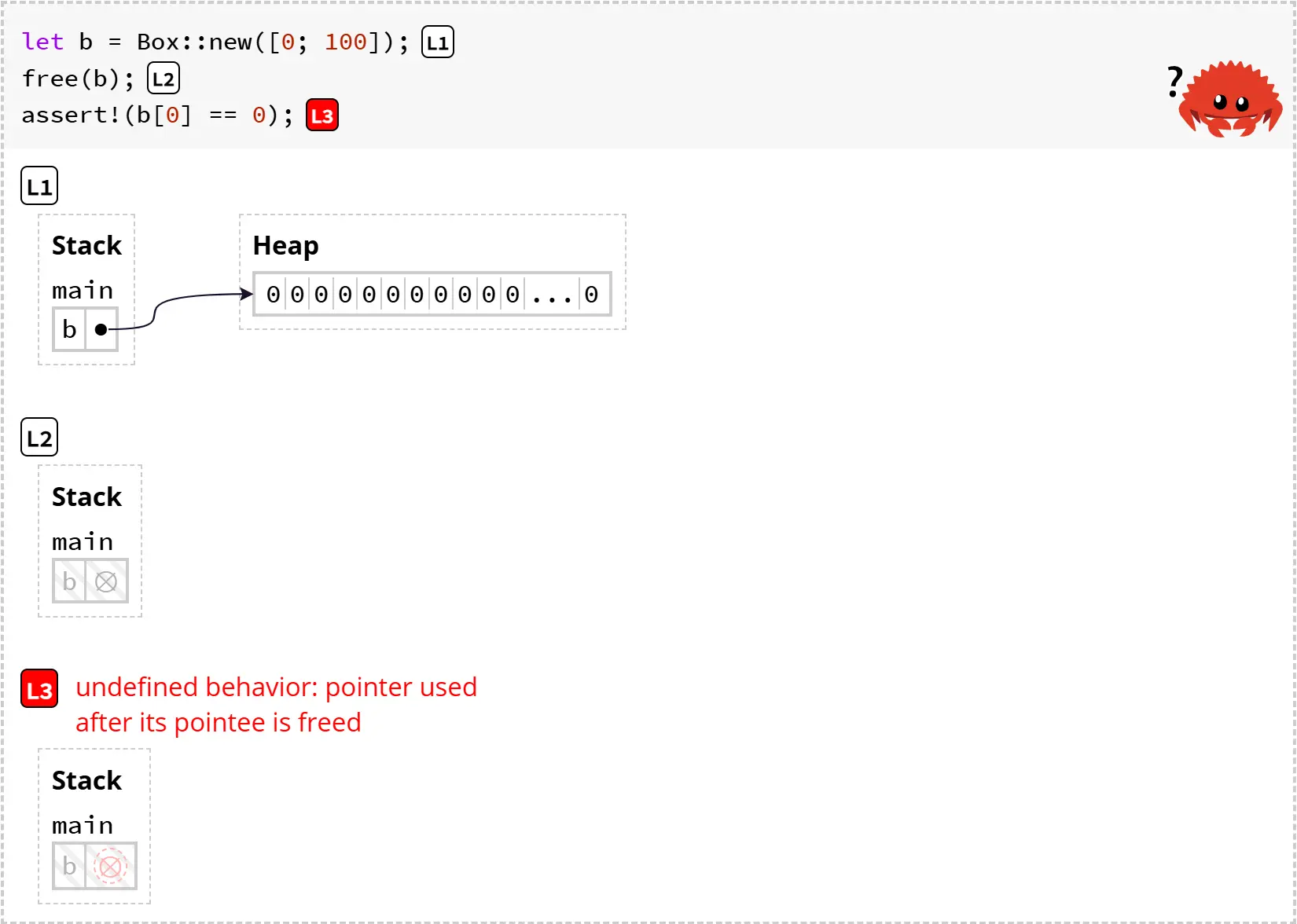
注意:你可能会好奇,为什么我们能运行这段 Rust 程序——实际上它是无法通过编译的。我们这里用的是一些特殊的工具,模拟一种没有借用检查器的 Rust,仅用于教学目的。这样我们才能讨论“如果 Rust 允许这个不安全的程序编译,会发生什么?”这样的问题。
在这个例子里,我们在堆上分配了一个数组。然后调用 free(b),释放了 b 指向的堆内存。因此,b 现在是一个悬空指针(失效的指针),用“⦻”这个符号表示。此时还没有发生未定义行为!程序在 L2 还是安全的。拥有一个无效指针本身并不一定是问题。
真正的未定义行为发生在我们尝试使用这个指针时,也就是读取 b[0]。此时程序会尝试访问无效内存,这可能会导致程序崩溃,或者更糟——它可能没有崩溃,却返回了任意数据。因此,这段程序是不安全的。
Rust 不允许程序员手动释放内存。这种设计就是为了避免上面这类未定义行为。
Box 的释放由其所有者负责管理 相反,Rust 会自动释放 box 在堆上分配的内存。这里有一个对 Rust 管理 box 释放策略的“几乎正确”的描述:
Box 释放原则(近似版):如果一个变量绑定到一个 box,当 Rust 释放这个变量所在的栈帧时,Rust 会同时释放 box 的堆内存。
举个例子,让我们来看一下一个分配并释放 box 的程序是如何执行的:
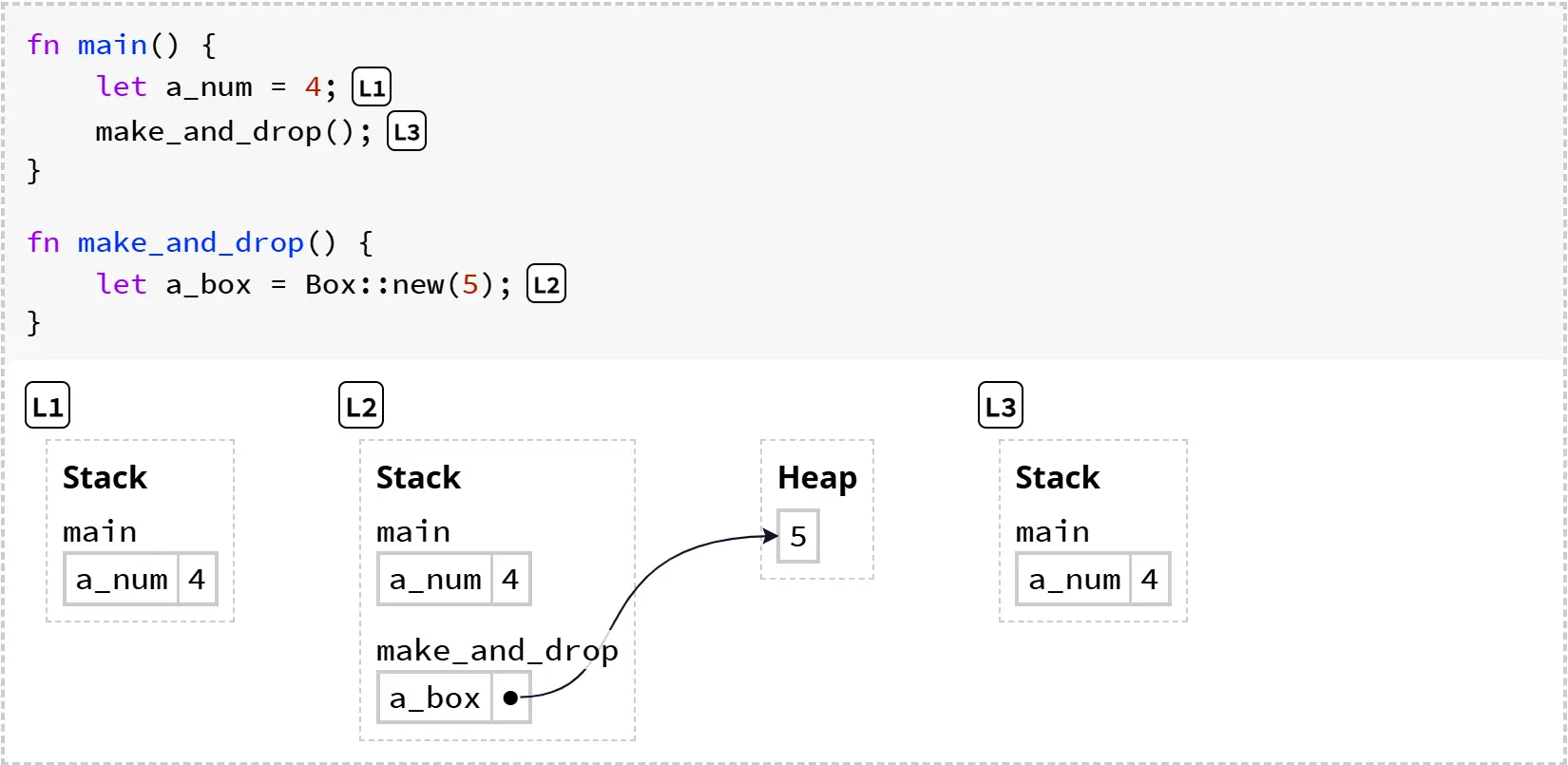
在 L1(调用 make_and_drop 之前),内存的状态只有 main 的栈帧。到了 L2(调用 make_and_drop 期间),a_box 指向堆上的数字 5。当 make_and_drop 结束时,Rust 会释放它的栈帧。由于 make_and_drop 包含了变量 a_box,Rust 也会释放 a_box 指向的堆内存。因此,L3 时堆内存已经被清空。
这样,box 的堆内存就被成功地自动管理了。但如果我们“滥用”这个机制会怎样?回到前面的例子,如果我们把同一个 box 绑定到两个变量上,会发生什么呢?
let a = Box::new([0; 1_000_000]);
let b = a;
2
现在,这个 box(装箱数组)被绑定到了 a 和 b 两个变量上。按照我们之前那个“几乎正确”的原则,Rust 会尝试为这两个变量分别释放 box 的堆内存,也就是释放两次。这同样是未定义行为!
为了避免这种情况,我们终于引出了“所有权”的概念。当 a 绑定到 Box::new([0; 1_000_000]) 时,我们说 a 拥有(owns)这个 box。let b = a 这条语句会把 box 的所有权从 a 移动(move)到 b。在有了这些概念后,Rust 释放 box 的策略可以更准确地描述为:
Box 释放原则(完全正确):如果一个变量拥有一个 box,当 Rust 释放该变量的栈帧时,会释放 box 的堆内存。
在上面的例子中,最后是 b 拥有这个装箱数组。因此作用域结束时,Rust 只会代表 b 释放一次 box,而不会为 a 也释放。
# 集合类型使用 Box
Rust 的许多数据结构(如 Vec、String 和 HashMap)内部其实都是用 box 来管理可变数量的元素的。例如,下面这个程序就展示了如何创建、移动和修改一个字符串:
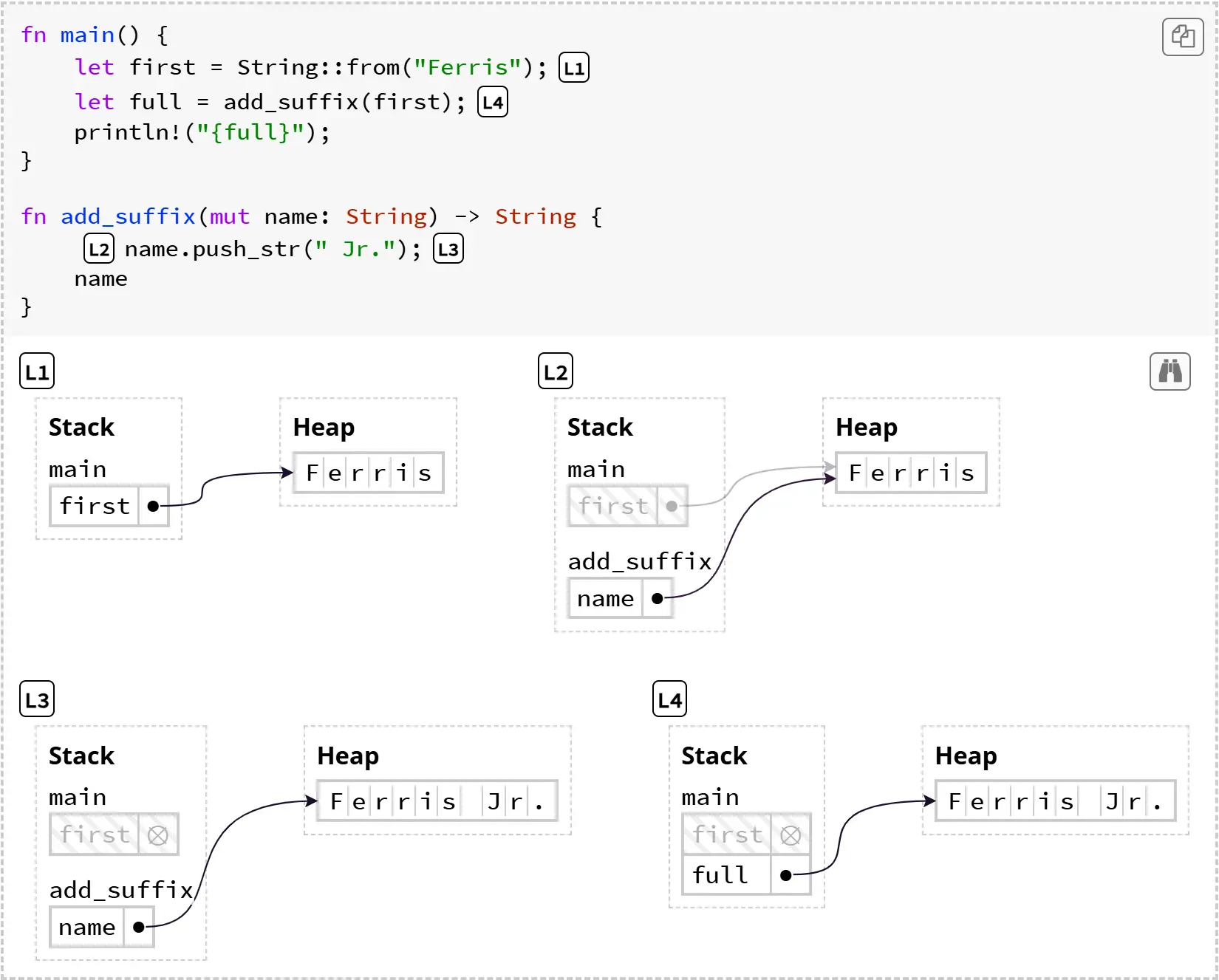
这个程序更复杂一些,请确保你能跟上每一步:
- 在 L1,字符串
"Ferris"被分配在堆上,它的所有者是first。 - 在 L2,调用了函数
add_suffix(first),这一步把字符串的所有权从first移动到了name。字符串的数据本身没有被复制,只是指向数据的指针被复制了。 - 在 L3,
name.push_str(" Jr.")会重新分配一块更大的堆内存。这一步包括三件事:第一,分配新的更大的内存;第二,把"Ferris Jr."写入新内存;第三,释放原来的堆内存。此时,first指向的已经是被释放的内存。 - 在 L4,
add_suffix的栈帧消失,这个函数返回了name,字符串的所有权随之转移给了full。
# 变量在被移动后不能再使用
这个字符串的例子帮助我们理解所有权的一个关键安全原则。假设我们在 main 调用 add_suffix 之后还继续使用了 first。我们可以模拟这种情况,并看到由此带来的未定义行为:
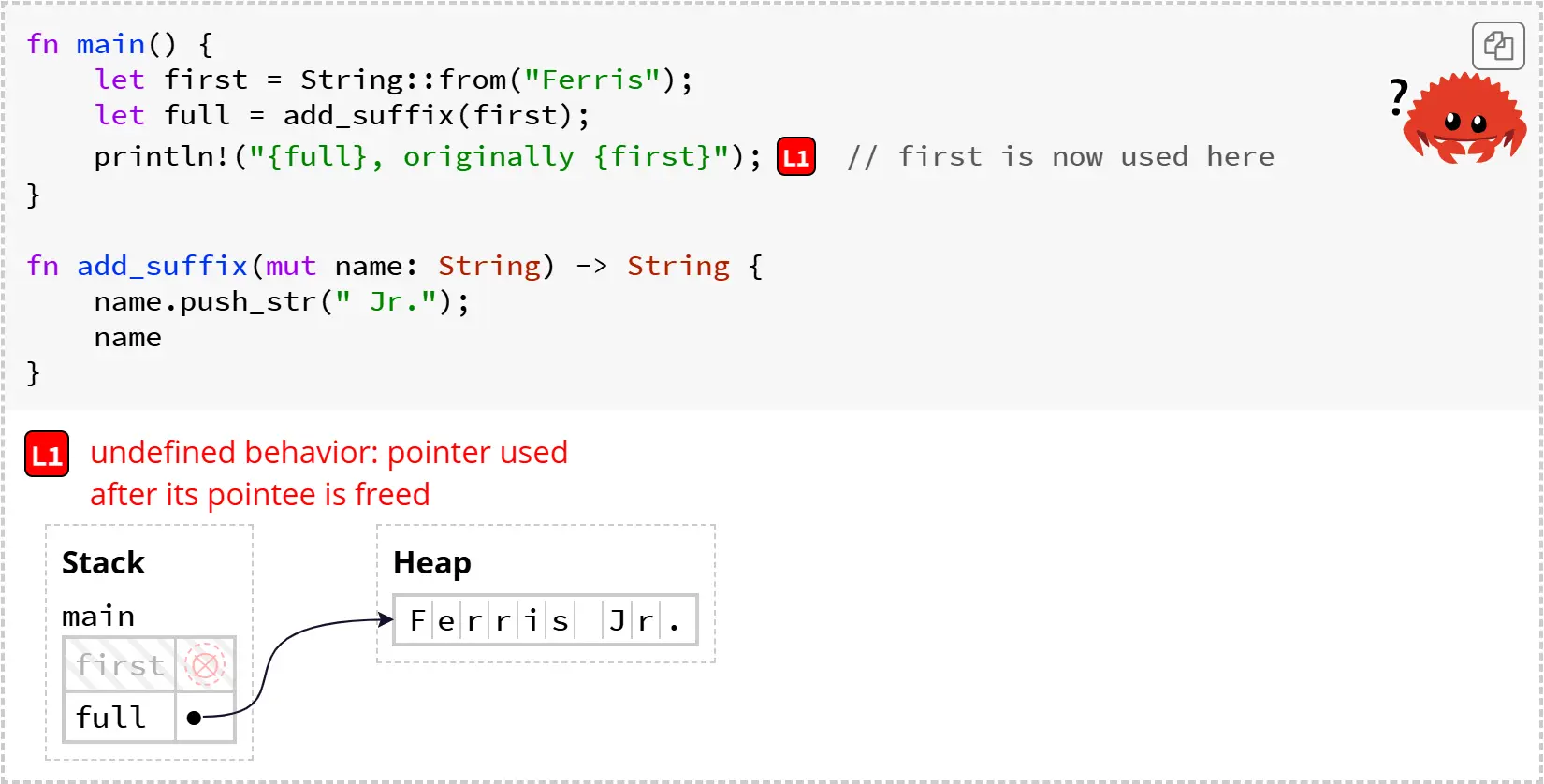
调用 add_suffix 之后,first 指向的是已经被释放的内存。如果在 println! 中读取 first,这就违反了内存安全(即产生了未定义行为)。请记住:first 指向已释放内存本身并不是问题,问题在于我们在 first 变为无效后还尝试使用它。
幸运的是,Rust 会拒绝编译这样的程序,并给出如下错误:
error[E0382]: borrow of moved value: `first`
--> test.rs:4:35
|
2 | let first = String::from("Ferris");
| ----- move occurs because `first` has type `String`, which does not implement the `Copy` trait
3 | let full = add_suffix(first);
| ----- value moved here
4 | println!("{full}, originally {first}"); // first is now used here
| ^^^^^ value borrowed here after move
2
3
4
5
6
7
8
9
让我们一步步来看这个错误提示。Rust 告诉我们,在第 3 行调用 add_suffix(first) 时,first 被移动了。错误信息还说明,first 被移动是因为它的类型是 String,而 String 没有实现 Copy trait。我们很快会介绍 Copy——简单来说,如果你用的是 i32 而不是 String,就不会出现这个错误。最后,错误信息指出,我们在变量被移动后还尝试使用了它(这里用的是“borrowed”,下一节会讲到)。
所以,如果你移动了一个变量,Rust 会阻止你之后再使用这个变量。更一般地说,编译器会强制遵循这样一个原则:
堆数据移动原则:如果变量
x把堆数据的所有权移动给了另一个变量y,那么在 move 之后,x不能再被使用。
现在你应该能看出所有权、move 和安全之间的关系了。通过移动堆数据的所有权,Rust 能防止因为读取已释放内存而产生的未定义行为。
# 克隆可以避免 move
一种避免数据被移动的方法是用 .clone() 方法来克隆它。例如,我们可以通过克隆来修复上面程序中的安全问题:
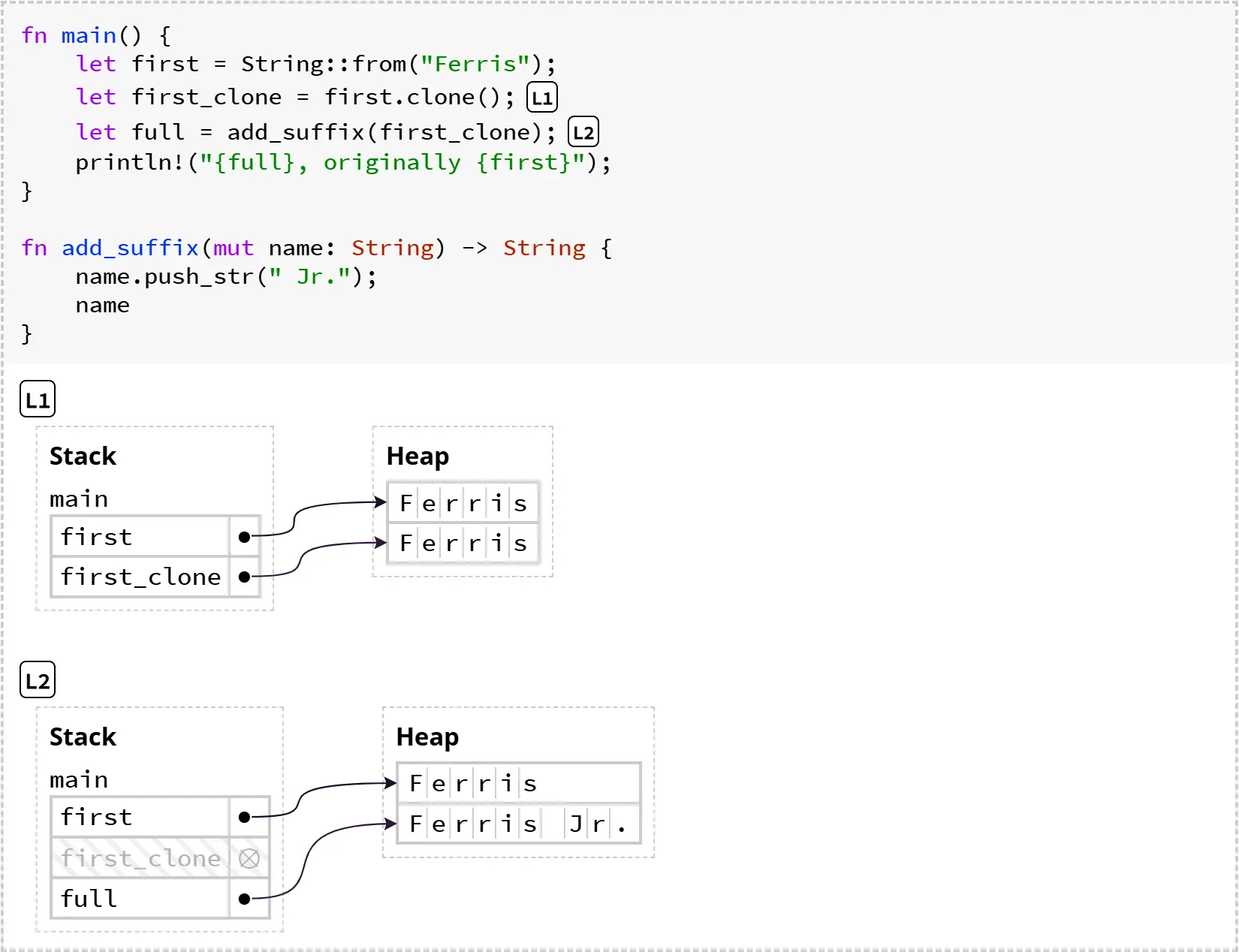
请注意,在 L1 时,first_clone 并不是对 first 的指针进行“浅拷贝”,而是把字符串数据“深拷贝”到了新的堆内存中。因此,在 L2 阶段,虽然 first_clone 的所有权被 add_suffix 移走、变量本身失效了,但最初的 first 变量并没有被影响。我们可以安全地继续使用 first。
如果你一时搞不懂为什么 Rust 会“抱怨”,也不用沮丧。这些概念基础应该能帮你更好地理解 Rust 的报错信息,也能帮你设计出更“Rust 风格”(Rustic)的 API。
这些数据结构其实并没有直接使用字面意义上的 Box 类型。例如,String 是通过 Vec 实现的,而 Vec 又是基于 RawVec 而不是 Box。不过,像 RawVec 这样的类型本质上也类似于 box:它们拥有堆上的内存。
从另一个角度来看,所有权其实也是一种指针管理的约束方法。但我们还没有讲到如何创建指向堆以外地方的指针,这部分内容我们会在下一节介绍。