 DINO-X
DINO-X
# 1 DINO-X
DINO-X: A Unified Vision Model for Open-World Object Detection and Understanding
DINO-X:用于开放世界目标检测与理解的统一视觉模型
https://github.com/IDEA-Research/DINO-X-API (opens new window)
2025年5月15日

图 1:DINO-X 是一个统一的对象中心视觉模型,支持多种开放世界感知与对象级理解任务,包括开放世界目标检测与分割、短语定位、视觉提示计数、姿态估计、无提示目标检测与识别、密集区域描述等。
# 2 摘要
本文介绍了 DINO-X,这是由 IDEA Research 开发的一个统一的对象中心视觉模型,在开放世界目标检测任务中达到了当前最佳性能。DINO-X 采用了与 Grounding DINO 1.5 相同的 基于 Transformer 的编码器-解码器架构,以实现对开放世界中对象级别表示的理解。
为了简化长尾类目标的检测,DINO-X 在输入方面扩展了支持,包括文本提示(text prompt)、视觉提示(visual prompt)和自定义提示(customized prompt)。基于这些灵活的提示选项,开发了一个通用对象提示(universal object prompt),从而实现了无需提示的开放世界目标检测 —— 用户无需提供任何输入即可检测图像中的任意对象。
为了增强模型的核心对齐能力(grounding capability),构建了一个包含超过 1 亿条高质量标注样本的大规模数据集,称为 Grounding-100M,以提升模型的开放词汇检测性能。在如此大规模的对齐数据上进行预训练,使 DINO-X 获得了基础的对象级表示能力,进而使其可以集成多个感知头(perception heads),同时支持多种对象感知与理解任务,包括:检测、分割、姿态估计、对象描述、基于对象的问答等。
DINO-X 包含两个模型版本:
- Pro 模型,具有更强的感知能力,适用于多种复杂场景;
- Edge 模型,优化了推理速度,更适合部署在边缘设备上。
实验结果表明 DINO-X 的性能显著优于现有方法。具体而言,DINO-X Pro 模型在 COCO、LVIS-minival 和 LVIS-val 的零样本目标检测基准上分别达到了 56.0 AP、59.8 AP 和 52.4 AP。尤其在 LVIS-minival 和 LVIS-val 的稀有类别上,分别获得了 63.3 AP 和 56.5 AP,比之前的 SOTA 方法分别提高了 5.8 AP 和 5.0 AP,凸显了其在识别长尾类目标方面的强大能力。DINO-X的演示和 API 将在以下地址发布: https://github.com/IDEA-Research/DINO-X-API (opens new window)
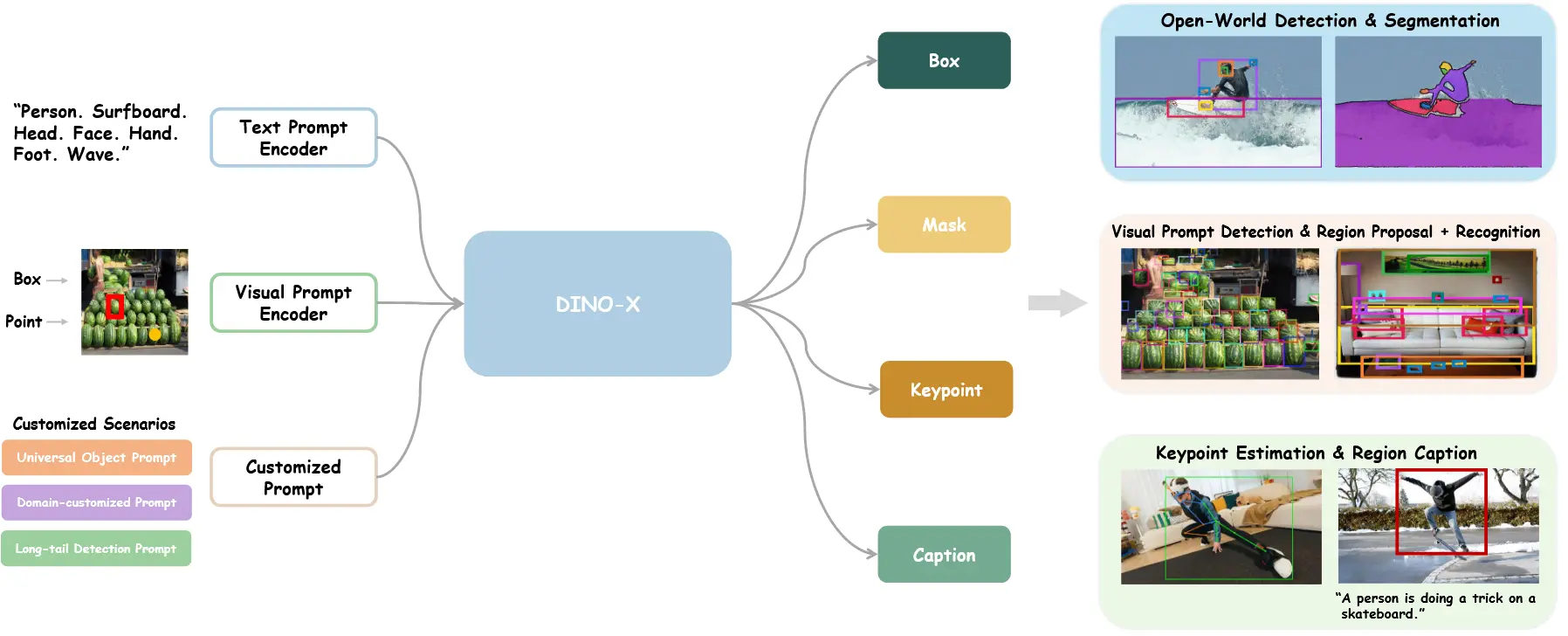
图 3:DINO-X 被设计为可接受文本提示、视觉提示和自定义提示,并能够同时生成从边界框等粗粒度表示到掩码、关键点和对象描述等细粒度细节的输出。
# 3 引言
近年来,目标检测已经逐渐从封闭集合(closed-set)检测模型发展为开放集合(open-set)检测模型,后者能够识别用户提供提示词所对应的对象。这类模型拥有广泛的实际应用,例如:增强机器人在动态环境中的适应能力、协助自动驾驶车辆快速定位和响应新对象、提升多模态大语言模型(MLLM)的感知能力、减少幻觉现象、并提高其响应的可靠性。
本文中提出了 DINO-X,这是一个由 IDEA Research 开发的统一对象中心视觉模型,在开放世界目标检测方面取得了目前最好的性能。DINO-X 构建于 Grounding DINO 1.5 的基础上,采用相同的 Transformer 编码器-解码器架构,并以开放集合检测任务作为核心训练目标。
为了简化长尾目标的检测问题,DINO-X 在模型输入阶段引入了更为全面的提示设计。传统的仅支持文本提示的模型虽然已经取得了较大进展,但仍难以覆盖足够多样化的长尾检测场景,原因在于难以收集足够丰富的训练数据来适配各种应用需求。
为了解决这一问题,DINO-X 扩展了模型架构,支持以下三种提示方式:
- 文本提示(Text Prompt):用户通过文字输入指定目标对象,适用于大多数常见检测场景。
- 视觉提示(Visual Prompt):除了文本提示外,DINO-X 还支持类似 T-Rex2 中的视觉提示,用于处理那些难以用语言准确描述的检测任务。
- 自定义提示(Customized Prompt):为进一步解决长尾检测问题,DINO-X 引入了可预定义或通过用户调优的自定义提示嵌入(prompt embedding),通过提示调优(prompt-tuning)技术,可以创建面向特定领域或功能的定制提示,以满足多样化的功能需求。
例如,在 DINO-X 中,我们开发了一个通用对象提示(universal object prompt),支持无提示的开放世界目标检测,使得模型可以在无需任何用户输入的情况下检测图像中的任意对象。
为了实现强大的对齐能力(grounding performance),我们从多个来源收集并整理了超过 1 亿条高质量对齐样本,构建了名为 Grounding-100M 的大规模数据集。在如此规模的数据上进行预训练,使得 DINO-X 学会了基础的对象级表示能力(foundational object-level representation),从而能够集成多个感知头模块,同时支持多种对象感知与理解任务。
除了用于目标检测的 Box Head,DINO-X 还实现了以下三个模块:
- Mask Head:用于预测检测目标的分割掩码;
- Keypoint Head:用于为特定类别预测更具语义意义的关键点(如人体姿态);
- Language Head:为每个检测到的对象生成细粒度的描述性文本(caption)。
通过这些模块的集成,DINO-X 能够实现更细致的图像对象级理解。与 Grounding DINO 1.5 类似,DINO-X 同样包含两个模型版本:
- DINO-X Pro:面向复杂场景,具有更强的感知能力;
- DINO-X Edge:优化推理速度,更适合部署在边缘设备上。
实验结果证明了 DINO-X 的卓越性能。如图所示,DINO-X Pro 在 COCO、LVIS-minival 和 LVIS-val 零样本迁移基准上分别达到了 56.0 AP、59.8 AP 和 52.4 AP。
特别是在 LVIS-minival 和 LVIS-val 的稀有类别上,DINO-X 分别达成 63.3 AP 和 56.5 AP,相较于 Grounding DINO 1.6 Pro 提高了 5.8 AP 和 5.0 AP,相较于 Grounding DINO 1.5 Pro 提高了 7.2 AP 和 11.9 AP,显著提升了对长尾类别的识别能力。
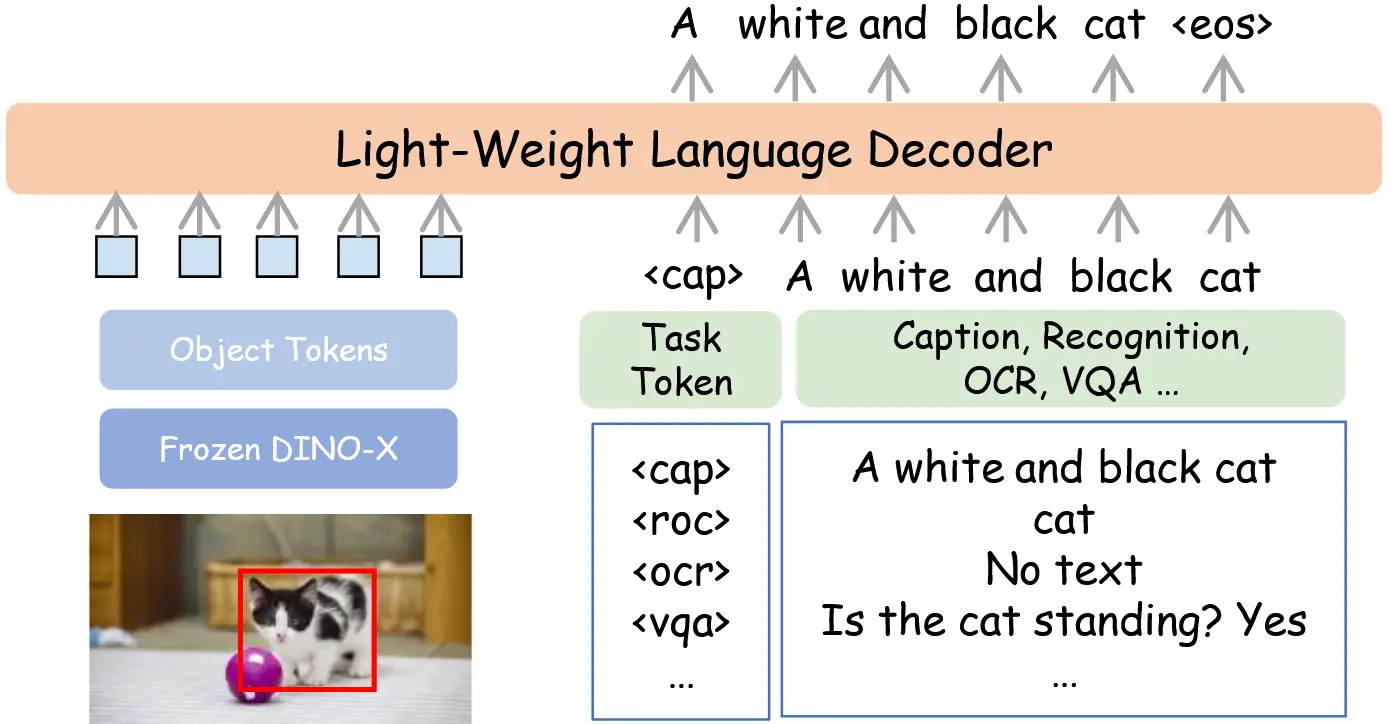
图 4:DINO-X 中语言头的详细设计。该模块首先使用冻结的 DINO-X 提取对象 token,并通过线性投影将其维度与文本嵌入对齐。随后,轻量级语言解码器将这些对象 token 与任务 token 融合,以自回归方式生成响应输出。任务 token 赋予语言解码器处理多种任务的能力。
# 4 方法
# 4.1 模型架构
DINO-X 的整体框架如图 3 所示。在延续 Grounding DINO 1.5 的基础上,我们同样开发了 DINO-X 的两个版本:
- 功能更强大、感知能力更全面的 “Pro” 版本(DINO-X Pro);
- 推理速度更快、适用于边缘部署的 “Edge” 版本(DINO-X Edge),将在第 2.1.2 节中详细介绍。
# 4.1.1 DINO-X Pro
DINO-X Pro 的核心架构与 Grounding DINO 1.5 相似,采用了预训练的 ViT 模型作为视觉骨干网络(backbone),并在特征提取阶段引入了深层次的早期融合策略(deep early fusion strategy)。
与 Grounding DINO 1.5 不同的是,为了进一步提升模型在长尾目标检测方面的能力,DINO-X Pro 在输入阶段扩展了对多种提示类型的支持:
- 文本提示(Text Prompts):适用于日常中大多数目标检测场景;
- 视觉提示(Visual Prompts):用于文本难以准确描述的检测场景,增强模型在描述受限、数据稀缺情况下的检测能力;
- 自定义提示(Customized Prompts):是一类可通过提示微调(prompt-tuning)方式进行适配和扩展的提示,支持构建面向长尾类别、特定领域或功能的专用提示嵌入,且不影响模型其他能力。
通过在大规模 Grounding 数据上进行预训练,DINO-X 获取了基础的对象级表示能力(foundational object-level representation)。这种强大的特征表达能力使我们可以灵活引入不同的感知头(perception heads),以支持多样的对象级感知与理解任务。因此,DINO-X 能够输出不同语义层级的结果,从粗粒度的边界框(bounding boxes),到更精细的分割掩码(masks)、关键点(keypoints)和对象描述(captions)等细粒度输出。
接下来将分别介绍 DINO-X 所支持的各类提示类型。
# 文本提示编码器(Text Prompt Encoder):
在 Grounding DINO 和 Grounding DINO 1.5 中,均采用 BERT 作为文本编码器。但由于 BERT 仅在文本数据上训练,缺乏多模态对齐能力,因此在开放世界检测等感知任务中表现有限。为了解决这一问题,DINO-X Pro 采用预训练的 CLIP 模型作为文本编码器。CLIP 在大规模多模态数据上进行了预训练,显著提升了模型在各类开放世界基准任务上的训练效率与性能。
# 视觉提示编码器(Visual Prompt Encoder):
DINO-X 采用了 T-Rex2 中的视觉提示编码器,支持用户定义的框(box)或点(point)形式的视觉提示,以增强目标检测能力。 具体实现包括:
- 使用 正余弦位置编码(sine-cosine layer) 将视觉提示转换为位置嵌入;
- 使用不同的线性投影区分 box 和 point 类型;
- 然后通过 T-Rex2 中的 多尺度可变形交叉注意力模块(multi-scale deformable cross-attention),从多尺度特征图中提取与用户提示相关的特征。
# 自定义提示(Customized Prompt):
在实际应用中,常常需要对模型进行微调以适应特定场景。DINO-X Pro 提供了自定义提示机制,支持通过 Prompt-Tuning 技术 来覆盖更多的长尾类别、领域特定任务或功能性需求场景。这种方式具有高效、低资源消耗、不影响原有能力等优点。
例如,DINO-X 中就开发了通用对象提示(universal object prompt),以支持无需任何提示输入即可执行的开放世界目标检测任务,这也使其具备了扩展到如**屏幕解析(screen parsing)**等领域的潜力。
给定一张输入图像以及用户提供的提示(无论是文本提示、视觉提示还是自定义提示嵌入),DINO-X 会对提示信息与从图像中提取的视觉特征进行深度特征融合,随后根据任务类型,调用不同的感知头模块(head)以完成相应的感知任务。
具体来说,DINO-X 实现了如下感知头:
# Box Head(边界框检测头)
- 采用 语言引导的查询选择模块(language-guided query selection),从视觉特征中筛选出与提示最相关的特征,作为 Transformer 解码器的对象查询(object queries)。
- 每个查询通过 Transformer 解码器逐层更新,随后经过一个简单的 MLP 层,预测对应对象的 边界框坐标。
- 损失函数采用:
- L1 损失与G-IoU 损失用于边框回归;
- **对比损失(contrastive loss)**用于将每个查询与提示进行对齐分类。
# Mask Head(分割掩码头)
- 借鉴 Mask2Former 与 Mask DINO 的核心设计,构建一个 像素嵌入图(pixel embedding map)。
- 像素嵌入图由:
- 主干网络输出的 1/4 分辨率特征,
- 和 Transformer 编码器中 上采样后的 1/8 分辨率特征融合而成。
- 将 Transformer 解码器中的每个对象查询与像素嵌入图做点积(dot-product),生成对应的掩码输出。
- 为提升训练效率:
- 仅在掩码预测中使用了 1/4 分辨率特征;
- 且仅对最终采样点计算掩码损失,避免全图计算,加速训练。
这些模块通过不同的感知头支持了从粗粒度的边界框检测到细粒度的区域分割等多层次的视觉理解。
# Keypoint Head(关键点检测头)
- 功能:该模块负责从 DINO-X 的检测结果中识别出相关类别(如“人”或“手”),并预测其关键点位置及可见性。
- 流程:
- 将每个检测结果视为一个查询(query);
- 每个查询被扩展为若干个关键点;
- 这些关键点通过多个 可变形 Transformer 解码器层(deformable Transformer decoder layers)处理,以预测最终的关键点坐标和可见性。
- 特点:该过程可以看作是简化版的 ED-Pose 算法,专注于关键点检测,不需重新考虑目标检测问题。
- 实现实例:
- 人体关键点检测 head:预设 17 个关键点;
- 手部关键点检测 head:预设 21 个关键点。
# Language Head(语言头)
功能:该模块是一个支持任务提示(task-promptable)的小型生成式语言模型,用于提升 DINO-X 在区域级别上的理解能力,支持:
- 目标识别、
- 区域描述(captioning)、
- 文字识别(OCR)、
- **区域级视觉问答(VQA)**等任务。
结构与流程:
- 对于任一检测到的目标:
- 使用 RoIAlign 算子 从 DINO-X 的 backbone 特征中提取其区域特征;
- 将该区域特征与目标的查询嵌入(query embedding)结合,形成 对象 token。
- 通过线性映射(linear projection)将对象 token 转换为与文本嵌入对齐的维度;
- 轻量语言解码器(lightweight decoder)将这些对象 token 与 可学习的任务 token(task token) 一起输入,使用自回归方式生成输出结果。
- 对于任一检测到的目标:
优势:
- 任务 token 具有可学习性,使语言头能灵活适配多种区域语言任务;
- 架构轻量、易于部署,同时具备良好的泛化能力。
综上,DINO-X 的 Keypoint Head 与 Language Head 模块进一步提升了模型对结构性人体信息和语义信息的理解能力,使其从目标检测扩展到更丰富的视觉理解任务。
# 4.1.2 DINO-X Edge
DINO-X Edge 延续了 Grounding DINO 1.5 Edge 的设计,使用 EfficientViT 作为骨干网络,以实现高效的特征提取,并结合类似的 Transformer 编码器-解码器架构。为进一步提升 DINO-X Edge 在性能与计算效率上的表现,我们在模型结构与训练策略上进行了如下优化:
# 更强的文本提示编码器(Stronger Text Prompt Encoder)
- DINO-X Edge 与 Pro 版一样,采用 CLIP 文本编码器,以实现更强的区域级多模态对齐能力。
- 实践中,大多数情况下的文本提示嵌入可以预先计算,因此不会影响视觉编码器和解码器的推理速度。
- 使用更强的文本编码器,通常能带来更优的检测性能。
# 知识蒸馏(Knowledge Distillation)
- 为提升 DINO-X Edge 的性能,我们从 Pro 模型中进行知识迁移,采用:
- 基于特征的蒸馏(对齐中间层特征表示);
- 基于响应的蒸馏(对齐预测输出 logits)。
- 通过这种方式,DINO-X Edge 在不增加计算开销的前提下,显著增强了零样本能力,优于 Grounding DINO 1.6 Edge。
# 改进的 FP16 推理(Improved FP16 Inference)
- 通过引入浮点乘法的归一化技术,我们能够将模型量化为 FP16 精度,且不会损失准确性。
- 得益于此,DINO-X Edge 在 推理速度上实现了显著提升:
- 达到 20.1 FPS(在 A100 上),
- 相较 Grounding DINO 1.6 Edge 提升了 33%(15.1 → 20.1 FPS),
- 相较 Grounding DINO 1.5 Edge 提升了 87%(10.7 → 20.1 FPS)。
总结:DINO-X Edge 在保持轻量级部署能力的同时,结合了强表达的文本编码器、知识蒸馏机制与高效的混合精度推理,实现了兼顾推理速度与零样本检测性能的优秀表现。
# 5 数据集构建与模型训练
# 5.1 数据收集(Data Collection)
为确保 DINO-X 具备开放词汇目标检测能力,我们构建了一个高质量、语义丰富的大规模对齐数据集 —— Grounding-100M,包含来自网络的超过 1 亿张图像。主要处理方式如下:
- 视觉提示预训练数据:借助 T-Rex2 的训练集,并结合部分工业场景数据,用于视觉提示(visual prompt)下的对齐训练。
- 分割训练数据:使用开源分割模型 SAM 与 SAM2 为部分 Grounding-100M 样本生成伪掩码标签(pseudo mask annotations),用于训练 Mask Head。
- 无提示检测数据:从 Grounding-100M 中采样高质量子集,利用其标注边框作为**无提示检测(prompt-free detection)**的训练数据。
- 语言理解训练数据:另收集了超过 1000 万条区域级理解数据,用于训练 Language Head。涵盖:
- 对象识别
- 区域描述(Captioning)
- OCR(文字识别)
- 区域级问答(QA)
# 5.2 模型训练(Model Training)
为解决多任务训练的复杂性,DINO-X 采用两阶段训练策略:
阶段一:多任务联合预训练
- 同时训练:
- 基于文本提示的检测;
- 基于视觉提示的检测;
- 目标分割任务。
- 训练阶段不使用 COCO、LVIS、V3Det 数据集,确保可以在这些基准上进行零样本检测评估(zero-shot evaluation)。
- 该阶段预训练使模型获得强大的开放词汇对齐能力与基础对象级表示能力。
阶段二:功能模块独立训练
- 冻结 DINO-X 主干(backbone),新增以下模块并分别训练:
- 关键点检测头(Keypoint Head):用于人体与手部;
- 语言头(Language Head):用于理解与生成文本相关任务。
- 同时使用 Prompt-Tuning 技术 训练一个通用对象提示(Universal Object Prompt),实现无提示目标检测,并保持其他能力不变。
两阶段训练策略的优势
- 保证核心的对齐能力不会因功能扩展而受损;
- 验证了大规模 grounding 预训练可以作为构建对象中心模型的稳固基础,并可无缝扩展至其他开放世界理解任务。